AI Brand Voice Strategy: How to Keep Voice Identity Consistent Across Every Touchpoint

A practical AI brand voice strategy to keep speech consistent across IVR, apps, and alerts using persona specs, a unified API architecture, and governance.
Your AI brand voice is not a toggle in a settings panel. It is a strategic asset, shaping how people perceive your company the moment it speaks. When someone interacts with your IVR, triggers the assistant inside your app, or receives an automated outbound call, the voice on the other end either strengthens the brand or chips away at it. Many companies obsess over visual guidelines and then treat voice like a one-and-done configuration.
This is for product managers, brand strategists, and voice AI engineers who need a voice identity that survives contact with scale. The goal is a usable framework for defining a voice persona, a technical plan for keeping that voice consistent across systems, and governance that prevents slow drift over time.
This article outlines a path from definition to production discipline:
What an AI brand voice actually means, the foundational definition and why it differs from a simple TTS voice selection.
How to build your voice persona, including the attributes, parameters, and documentation that constitute a real voice identity.
Technical consistency across touchpoints, covering APIs, voice cloning, and deployment architecture.
Governance and drift prevention, detailing how to stop voice identity from degrading over time.
Advanced considerations like multilingual consistency, emotional range, and edge cases.
Common questions on implementation and maintenance.
What an AI Brand Voice Actually Means
A frequent confusion is that choosing a text-to-speech voice from a dropdown is the same as having an AI brand voice strategy. A voice model is the instrument. A brand voice is the instrument plus the persona it performs, the emotional register it is allowed to occupy, the pacing and prosody that signal “this is us,” and the discipline to keep those choices consistent wherever your brand speaks.
Picture a customer who calls support and hears a warm, measured voice, then opens your app and gets something clipped and robotic. Even if both are “fine” on paper, that mismatch signals internal fragmentation. Salesforce’s State of the Connected Customer report found that a significant majority of customers expect consistent interactions across departments. Voice is effectively a department, and it should be held to the same standard.
A workable AI brand voice strategy stacks three layers. First, acoustic identity: the voice model itself, timbre, accent, and baseline prosody. Second, behavioral identity: how that voice handles different content types, emotional contexts, and speaking rates. Third, governance: the processes, documentation, and tooling that keep the first two layers stable as your product grows. Many teams stop after layer one, then act surprised when the voice feels “off” six months later.
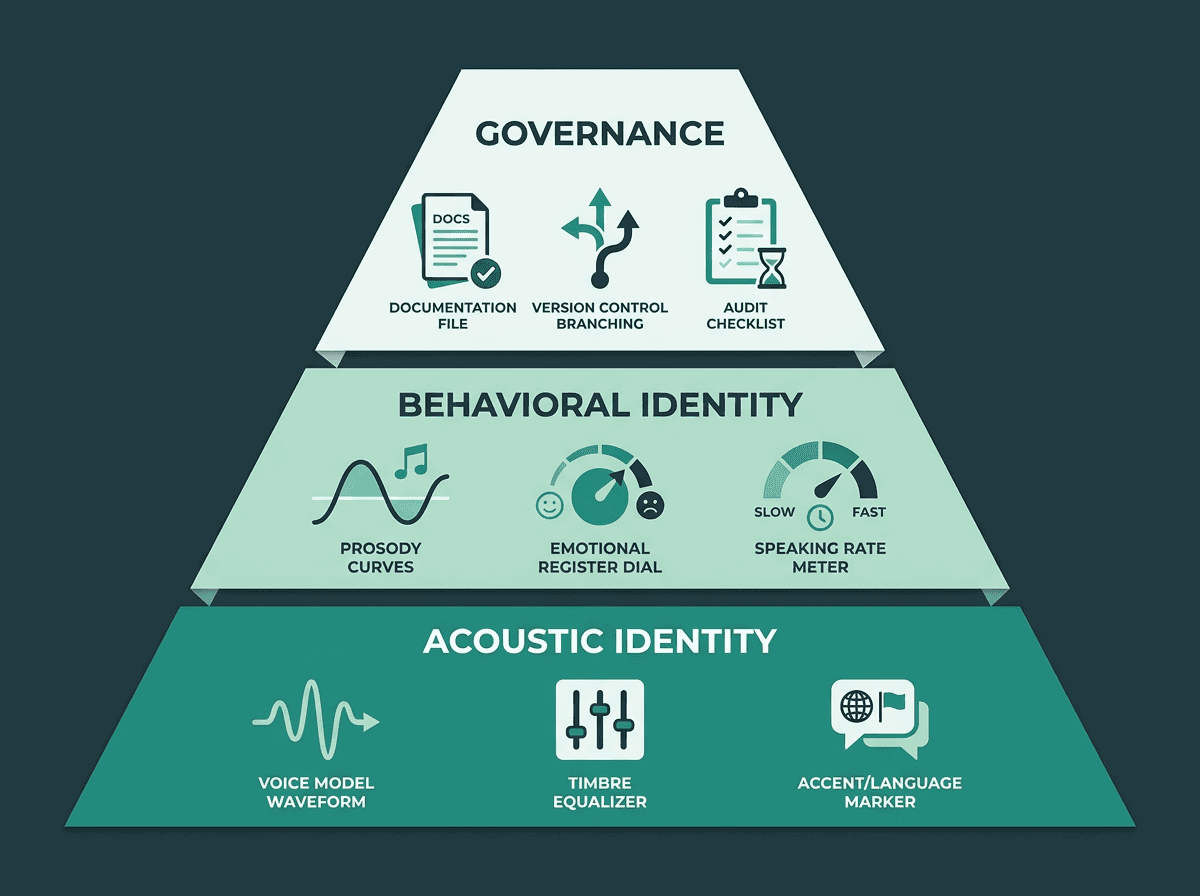
Building Your Voice Persona: The Attributes That Matter
Before you touch an API or tweak a parameter, write the voice persona document. This is not “creative writing” for a workshop; it is the spec you will use to judge every future voice decision. Without it, teams make inconsistent calls under deadline pressure, and those small inconsistencies compound into brand drift.
A voice persona document needs to be explicit about a few core attributes. Begin with personality anchors: three to five adjectives describing how the voice should land with a listener. “Confident but not aggressive. Warm but not casual. Precise but not cold.” Those anchors become the test for downstream choices about pacing, emphasis, and prosody. Then define emotional range: which emotions the voice can express, how strongly, and in which scenarios. A healthcare brand might live in calm reassurance almost everywhere, while a fintech brand might be authoritative for alerts and more approachable during onboarding. Same acoustic model, different voice identity.
Spell out speaking rate ranges by content category. A one-line notification does not behave like a long-form explainer, and a system that gets no rate guidance will default to one cadence that is wrong for a big chunk of your surfaces. Close with what the voice is not. The negative space is often the most useful part of the doc because it blocks the predictable failure modes before they ship.
Technical Consistency: Architecture Decisions That Protect Voice Identity
Voice identity usually breaks at the infrastructure layer, not in a brand brainstorm. The pattern is familiar: one team ships a branded IVR with Provider A. Six months later, another team builds an in-app assistant with Provider B because the first vendor’s SDK does not fit. A third team wires up notifications and leaves the default system voice in place. You do not end up with “a voice.” You end up with a small choir, none of it coordinated.
One practical way to enforce brand consistency is a single voice API layer that every surface calls. When every touchpoint routes through the same synthesis layer, you get central control over acoustic output. Voice model updates, parameter tuning, and persona refinements roll out everywhere instead of turning into a scavenger hunt across integrations.
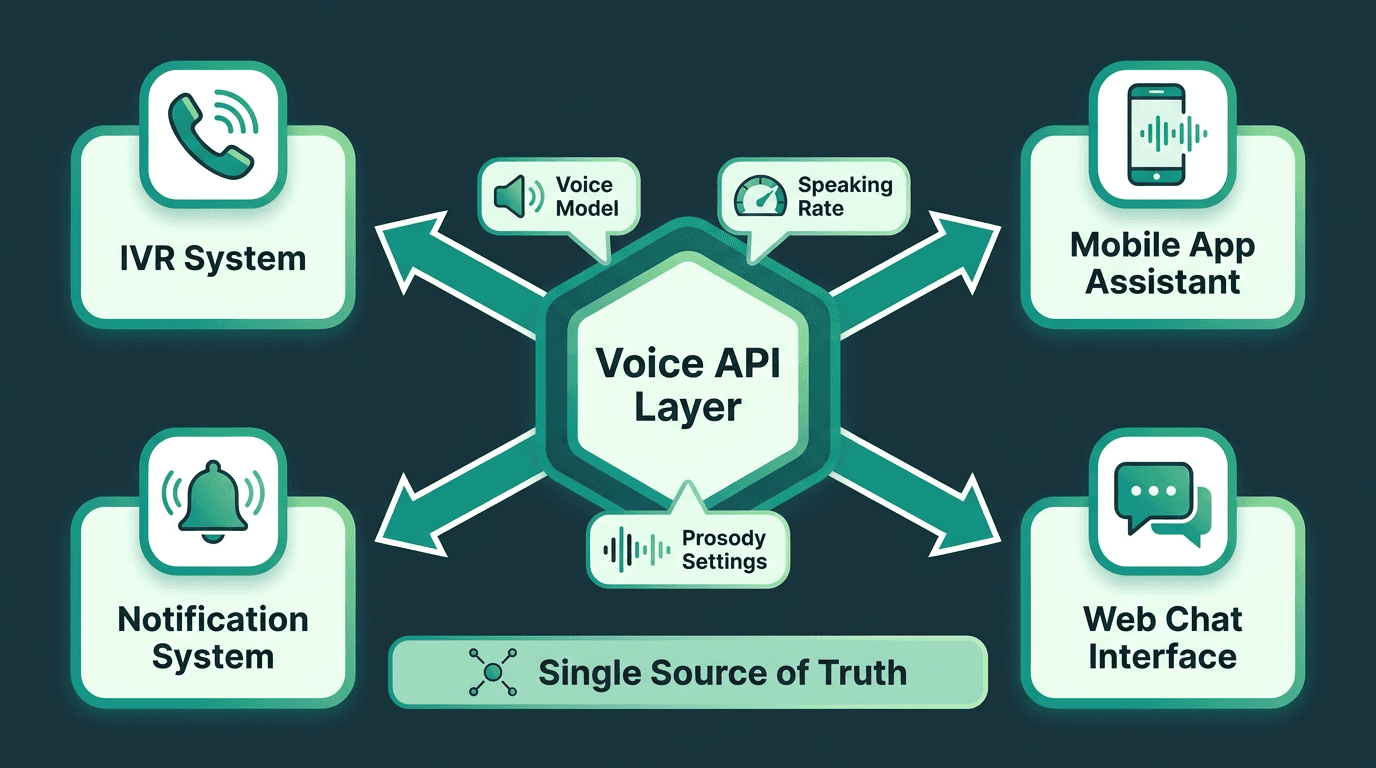
A single voice API layer ensures all product surfaces share the same acoustic identity.
Voice cloning fits naturally into this setup. Instead of picking an off-the-shelf voice that vaguely resembles your persona, you can build a proprietary model trained on recordings that actually embody it. Treated properly, that model is a brand asset in the same category as a logo or typeface. Smallest.ai's Lightning text-to-speech lets you create a custom voice model and deploy it through a single API across every surface, avoiding the acoustic drift you get when different platforms quietly pull you toward different stock voices.
SSML (Speech Synthesis Markup Language) is the day-to-day tool for keeping behavior consistent once the architecture is in place. Standardize SSML templates by content type and you get predictable delivery even when the text varies wildly. An “alert” template might bump speaking rate slightly and insert a short pause before the key detail. An “onboarding” template might slow down and allow more expressive prosody. Keep those templates centralized and versioned, and your persona document stops being aspirational, it becomes audible output.
Mapping Voice Behavior Across Specific Touchpoints
Consistency does not mean everything sounds identical. A brand voice that reads a 30-second notification the same way it handles a 10-minute onboarding flow has not been adapted; it has been pasted. What you want is continuity (recognizably the same voice) without forcing uniform delivery everywhere. Here is how that plays out across common touchpoints.
Touchpoint-specific voice behavior guidelines:
IVR and phone systems: Prioritize clarity and measured pacing. Callers are often in motion or under stress. The voice should project calm authority. Avoid expressive prosody variations that work well in other contexts but feel theatrical on a phone call.
In-app voice assistants: This is where warmth and personality can be expressed most fully. Users are in a low-stress, exploratory context. The voice can use a slightly faster rate and more natural prosody variation without feeling out of place.
Automated outbound calls: These require a high degree of naturalness because the listener has not opted into a voice interaction. The voice must sound genuinely human enough to hold attention without triggering the uncanny valley. Speech-to-speech models handle this context better than standard TTS because they can adapt in real time.
Notifications and alerts: Short-form content demands precision. Every word is load-bearing. The voice should read these with slightly elevated clarity and minimal prosody decoration. The message is the focus, not the voice.
Multilingual deployments: See the advanced section below. This is where many brand voice strategies have unaddressed gaps.
To manage these variations without improvising every time, use a voice behavior matrix: a living document mapping each touchpoint to its SSML parameters, content templates, and persona “intensity.” It sits next to the persona document and gets updated whenever a new surface ships. Skip the matrix and teams will make touchpoint-by-touchpoint judgment calls, the exact mechanism that starts drift. For more on dynamic adaptation, you can review the mechanics of how conversational AI workflows adapt brand voice.
Governance: Preventing Voice Identity Drift Over Time
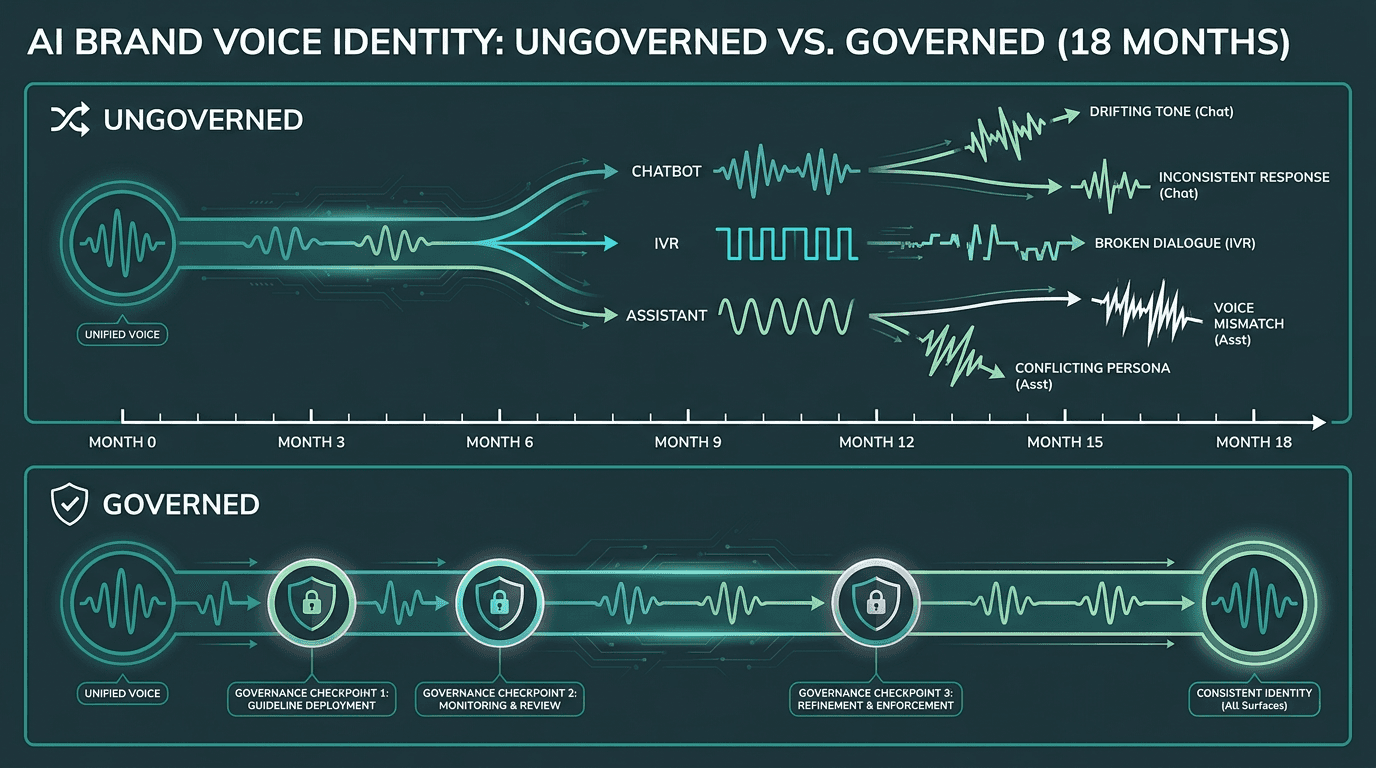
Without active governance, voice identity fragments across touchpoints within months.
Voice identity drift is the slow, mostly invisible way a brand starts sounding different depending on where you meet it. It rarely comes from reckless decisions. One team upgrades a TTS model because the new version sounds better. Another tweaks speaking rate after feedback that the voice feels sluggish. A third adds a localized voice for a new market without checking the persona doc. Each move makes sense locally; together they produce a brand that cannot keep a straight face.
Governance is what stops voice decisions from being made in isolation. A minimum viable setup has three parts. First, a voice owner: a named person or small team accountable for the persona document, the behavior matrix, and approvals. Second, a change protocol: a lightweight process that requires any proposed change to include the reason, the affected touchpoints, and the persona section that justifies it. Third, a periodic audit: a scheduled review (quarterly at minimum) where you sample audio from each touchpoint and score it against the persona.
Audits are where teams most often cut corners. Reviewing scripts or SSML in a doc will not catch what users actually hear. You need production renders, because models get updated, infrastructure shifts, and real-world content creates edge cases that push output away from your intent even when the settings look “right.”
Advanced Considerations: Multilingual Voice, Emotional Range, and Edge Cases
Most brand voice playbooks stop right before the messy parts. Three problem areas deserve to be treated as first-class requirements.
Multilingual voice consistency is where strategies most often fail quietly. The usual instinct is to pick a “similar sounding” voice in each language and declare victory. That breaks down fast because persona traits are culturally shaped. What reads as “warm and authoritative” in English can come across as overly formal in Brazilian Portuguese or not direct enough in German. The better approach is to re-evaluate your persona anchors per language and define what those anchors sound like in that language, instead of chasing a phonetic twin of your English voice. For more detail, see our guide to multilingual voice generation.
Emotional range calibration is subtler, and easier to get wrong. Modern TTS can express a lot of tone, which is useful right up until it is not. Enthusiasm in a fraud alert, or calm neutrality in a celebratory onboarding moment, is not “personality”; it is a mismatch. Your behavior matrix should specify emotional register per content type and set a ceiling on expressiveness. Too much emotional color can damage brand perception as quickly as monotone delivery.
Edge cases in content are where SSML templates prove their worth. Proper nouns, technical terms, mixed-language strings, and number formats can all produce surprising audio if you do not handle them deliberately. Treat a pronunciation lexicon as part of your governance infrastructure: a centrally maintained list of words and phrases that need explicit phonetic guidance, applied across touchpoints. It is not glamorous, but it is the work that keeps a voice sounding solid outside a demo script.
Three advanced challenges that separate durable voice identity strategies from shallow implementations.
From Concept to Production
A voice strategy that lasts is built in layers. Acoustic identity gives you the raw sound. Behavioral identity turns that sound into a persona that behaves appropriately across contexts. Governance is what keeps both intact as the product scales, the organization changes, and the stack gets refactored. Leaving any layer out results in shipping something coherent on day one, then spending the next year listening to it fragment.
Five actions move you from concept to implementation:
Write a voice persona document with personality anchors, emotional range definitions, and explicit "not this" boundaries before selecting any voice model.
Build or commission a proprietary voice model through voice cloning rather than relying on shared off-the-shelf voices that any competitor can also use.
Establish a single voice API layer that all product touchpoints route through, eliminating the multi-provider fragmentation that causes acoustic drift.
Create a voice behavior matrix that maps SSML parameters and emotional register to each content type and touchpoint.
Assign a voice owner, implement a change protocol, and schedule quarterly audio audits against your persona document.
The thread running through all of this is not “be more creative.” It is operations. Most teams want voice consistency; they just do not build the architecture and governance to deliver it across teams and over time. Smallest.ai's AI voice platform is designed for that operational reality, providing a unified brand voice infrastructure where identity parameters, persona configurations, and behavioral rules are managed centrally. If you are building or scaling a voice AI product and want the voice at touchpoint fifty to feel as deliberate as touchpoint one, you can read the Waves API documentation or book a demo.
What is an AI brand voice, and how is it different from picking a TTS voice?
How do I maintain voice consistency when my product spans multiple languages?
How often should we audit our AI brand voice for consistency?
Can voice cloning be used to create a consistent brand voice across all touchpoints?
What is the biggest mistake companies make with their AI brand voice strategy?

