Voice Agent API Guide: Architecture, Latency, Streaming, and Stack Choices


Voice Agent API essentials: how STT-LLM-TTS pipelines work, where latency really comes from, common mistakes, and what to check before choosing a stack.
Not long ago, a “voice interface” was basically a phone tree: press 1 for billing, press 2 for support, then sit through a hold queue. People put up with it because they had to. Now the bar is closer to human conversation: quick turn-taking, context that carries across turns, and responses that arrive fast enough that the silence does not feel like a crash. That shift has turned "voice" into a very specific engineering challenge: building systems that can keep up in real time.
Voice Agent APIs sit at the infrastructure layer that makes that bar reachable. They expose the whole conversational loop over an API, not just transcription or playback as standalone utilities. The goal here is to pin down what a Voice Agent API really is, how the pipeline behaves in practice, where teams tend to underestimate the work, and what to scrutinize before you lock in a stack.
What Is a Voice Agent API? (The Definition That Actually Holds Up)
A Voice Agent API is a programmatic interface for building real-time conversational systems that listen to speech, infer intent, and answer back with synthesized audio inside a single low-latency pipeline. The point is not that it includes STT or TTS; it is that it coordinates them with a reasoning layer so the experience behaves like a dialogue instead of a set of disconnected audio calls.
That difference is not semantics; it changes what you have to engineer. A TTS API turns text into audio. An STT API turns audio into text. A Voice Agent API stitches those ends together through a reasoning layer and keeps track of state across turns, so the system can handle back-and-forth, corrections, and interruptions without resetting the conversation each time. The “agent” part implies memory of what was said, awareness of what the user is trying to do, and behavior that can cope with ambiguity instead of collapsing into one-shot transactions. For a broader view of how this shows up in production architectures, the AI voice agent architecture overview breaks down the common structural patterns.
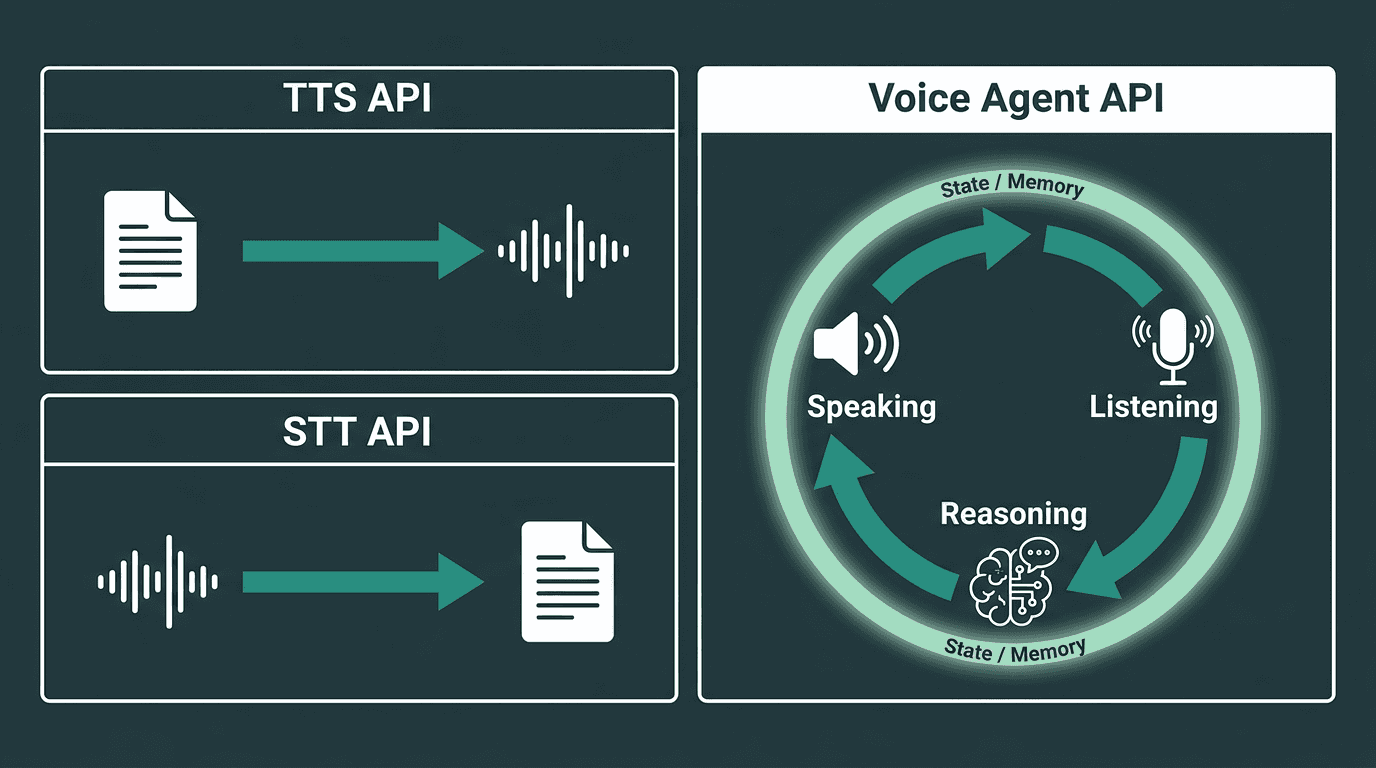
A Voice Agent API closes the loop that TTS and STT APIs each handle only half of.
The Stack Behind a Voice Agent: How It Actually Works
A voice agent pipeline is a relay of specialized models, coordinated by an orchestration layer. The standard order looks like this: speech-to-text converts incoming audio into a transcript; a language or conversational model interprets the transcript and drafts a response; text-to-speech turns that response into audio. Every handoff costs time, which is why latency ends up as the defining constraint. If it takes 2.5 seconds to deliver the first byte of audio, the system will feel broken to anyone expecting a natural exchange, even if the underlying models are “smart.”
One architectural choice separates production systems from decent demos: streaming vs. batch. Batch means each stage waits for a complete output before passing anything along. Streaming means partial outputs flow downstream as they are generated. For real-time voice agents, you do not get to treat streaming as an optimization; it is the mechanism that makes sub-second perceived latency possible.
Speech-to-Text: The Listening Layer
The STT layer turns raw audio into text as the user speaks. Its accuracy, typically tracked via Word Error Rate (WER), sets the ceiling for everything that follows. When transcription errors are high, the downstream model has to infer missing or incorrect intent, which can show up as wrong answers, unnecessary clarifying questions, or failed task completion. With streaming STT, partial transcripts arrive mid-utterance, which lets orchestration start intent processing before the user finishes the sentence and trims real time off the response. Smallest.ai’s Pulse is built as an STT component for this exact context, optimizing for streaming accuracy over batch throughput.
The Brain: Language Model or Conversational SLM
The language model layer reads the transcript, tracks dialogue state across turns, and produces the text the agent will speak. In voice, time-to-first-token is just as visible as response quality. Large general-purpose models can write excellent text, but they often spend hundreds of milliseconds before emitting the first token; stack that delay on top of TTS startup time and the agent starts to feel sluggish. Smaller conversational models (SLMs) are often a better fit for voice because they cut that first-token delay dramatically. Smallest.ai’s Electron is a conversational SLM built around that constraint: fast enough to keep the loop responsive, while still handling multi-turn dialogue without dropping context.
Text-to-Speech: The Voice Layer
The TTS layer converts the generated text into audio, and it is where “assistant” turns into “voice.” Quality determines whether the agent sounds natural or like a talking appliance. With streaming TTS, playback can begin before the full response text is finished, which is how you get the first audio byte out quickly even when the agent has a longer answer. Smallest.ai’s Lightning TTS is designed for streaming synthesis with low latency as a primary goal. When the pipeline needs to be compressed further, Hydra supports speech-to-speech conversion, reducing some inter-component overhead by staying closer to the audio domain. For a more technical walkthrough of how these pieces reduce delay, building faster AI voice agents digs into the latency mechanics.
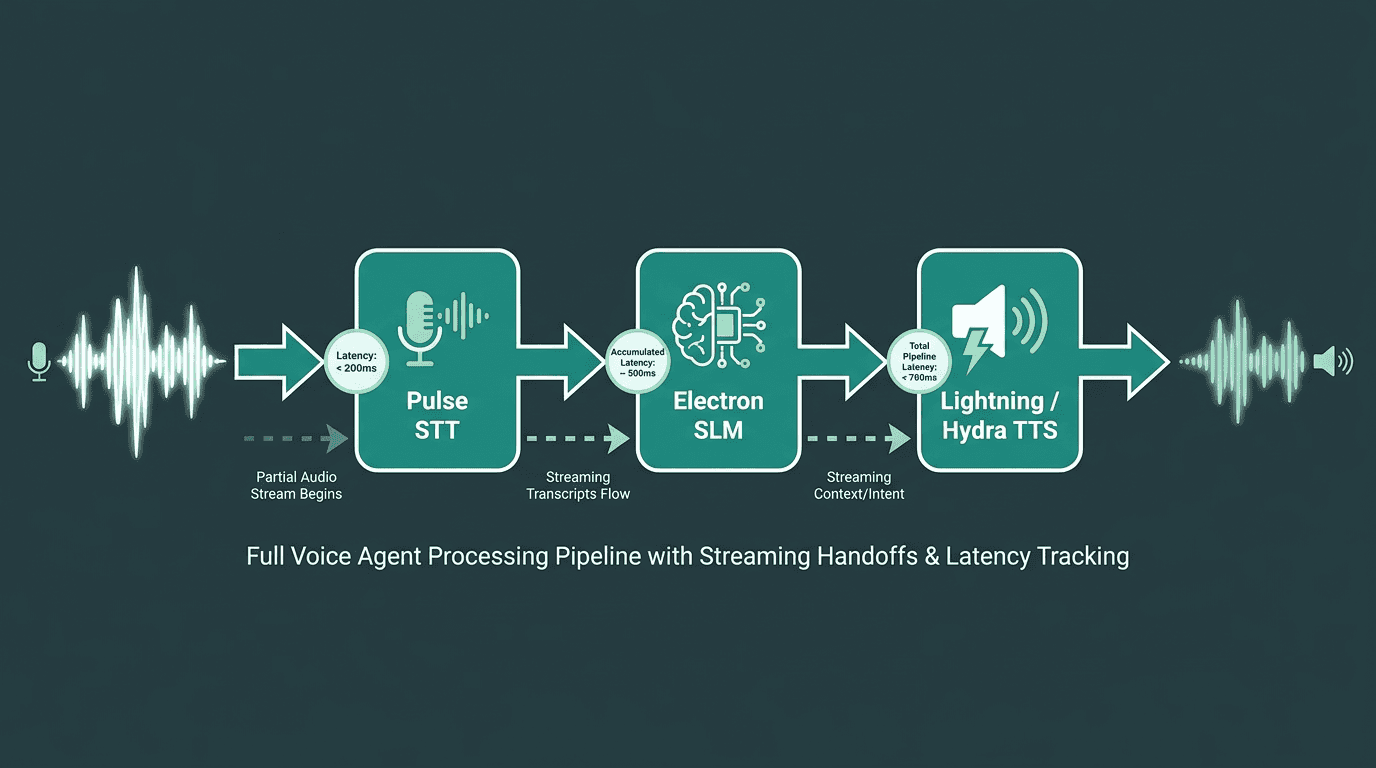
Streaming at every stage, STT through TTS, is what separates a responsive agent from a sluggish one.
Types of Voice Agent APIs: Not All Pipelines Are Built the Same
Voice Agent APIs generally land in three buckets, and each one forces real trade-offs across latency, control, and cost. Fully managed platforms take care of orchestration, model selection, and infrastructure, which lowers setup effort but also limits how deeply you can tune each layer. Modular component APIs let you assemble a pipeline from separate STT, LLM, and TTS services; you gain control, but you also inherit integration work and the extra latency that comes from hopping between services. Speech-to-speech APIs collapse the chain into a single model that maps input audio to output audio; that can cut latency sharply, but it often comes with thinner dialogue-state handling and fewer customization levers.
API Type / Platform | Setup Complexity | End-to-End Latency | Customization Depth | Best Use Case | Pricing Model |
|---|---|---|---|---|---|
Smallest.ai (Atoms / Waves API) | Low to Medium | Optimized for low-latency streaming | High (voice cloning, SLM tuning, prosody control) | Production voice agents where speed and brand voice both matter | |
Fully Managed Platform | Low | Medium (platform-controlled) | Low to Medium | Fast prototypes and standard, repeatable use cases | Per-minute or subscription |
Modular Component APIs | High | Medium to High (inter-service hops) | Very High | Specialized pipelines and custom research work | Per-component, variable |
Speech-to-Speech APIs | Low | Low (single model) | Low (limited dialogue state) | Simple interactions with few turns | Per-minute or per-request |
Where Voice Agent APIs Are Actually Being Used
Industries seeing real production deployments:
Customer support automation: AI voice agents handling Tier-1 inbound calls without human escalation.
Healthcare scheduling and patient intake: Outbound and inbound agents confirming appointments, collecting intake information, and routing patients to the appropriate care pathway. The structured, predictable nature of these conversations makes them well-suited to current voice agent capabilities.
Sales development: Outbound voice agents qualifying leads at scale, handling objection scripts, and booking meetings. The economics work when the cost per qualified conversation is lower than human SDR time.
Accessibility tooling: Real-time voice interfaces for users with motor impairments, where a responsive, low-latency agent is not a convenience feature but a functional requirement.
Three Things Developers Get Wrong About Voice Agent APIs
Misconception 1: 'Latency is a TTS problem.' When teams first feel the lag, they often blame speech synthesis. In real pipelines, the STT-to-LLM handoff is frequently the bigger drag. In a naively assembled stack, the gap between the user finishing a sentence and the first language-model token showing up can easily run 400–600ms. TTS tuning still matters, but it is usually the last knob to turn, not the first.
Misconception 2: 'A great LLM means a great voice agent.' Conversational quality is an end-to-end property. Pair a top-tier language model with high-WER transcription or a robotic-sounding voice and the user experience still falls apart. In voice systems, the weakest link is often whichever layer was selected without a hard requirement for streaming support.
Misconception 3: 'Voice cloning is a nice-to-have.' If the agent represents a brand, voice identity is part of the product, not window dressing. A generic synthetic voice signals “automated system” the moment it speaks. A consistent branded voice (cloned from a real person or designed intentionally) changes how callers interpret the agent’s competence and reliability. The W3C’s Smart Voice Agents workshop report highlights privacy-preserving authentication, user identification, accessibility, and interoperability as key areas for future standards work, which shows how central trust and identity are becoming in voice-agent systems.
What to Look for in a Voice Agent API Before You Commit to a Stack
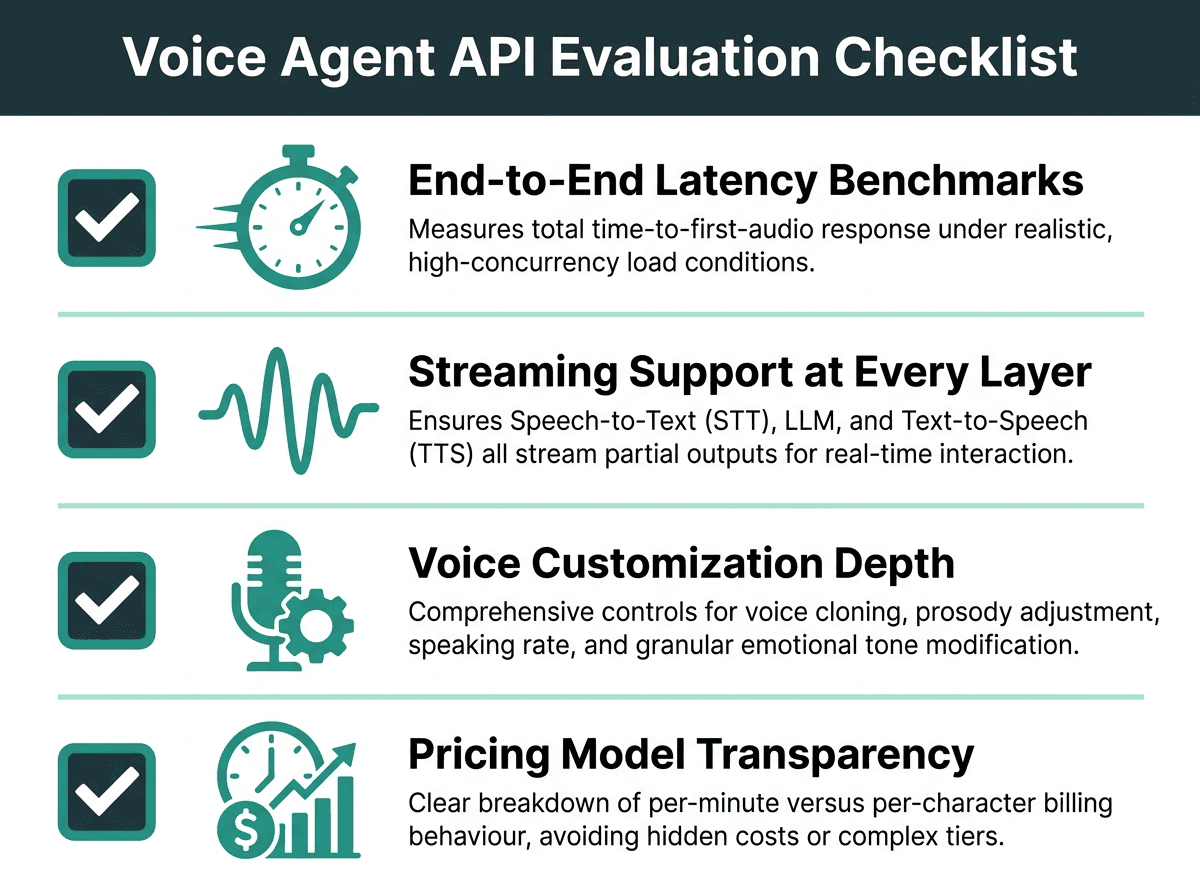
Four criteria that separate production-ready voice agent APIs from ones that look good in demos.
End-to-end latency benchmarks. Push vendors for time-to-first-audio numbers under realistic load, not a best-case demo run in a quiet lab. The gap between conversational and “did it freeze?” can be a matter of milliseconds. You want clarity on how latency targets and cost constraints collide before you scale.
Streaming support at every layer. Real-time agents live or die on this. Verify that STT, the language model layer, and TTS all stream partial outputs. A platform that streams TTS but batches STT has not removed latency; it has just relocated it upstream.
Voice customization depth. Check what is actually controllable over the API: voice cloning from samples, prosody controls, speaking rate, and emotional tone. For brand-consistent agents, these are not exotic features; they are table stakes. Pricing matters here too: understanding the costs of operating a voice agent at scale means knowing how customization features are billed relative to standard synthesis.
Pricing model transparency. Per-minute, per-character, and per-request pricing all behave differently once you are running real conversations. A per-character TTS plan can look cheap for short replies and then spike when the agent starts delivering longer explanations. Model your expected turn length and conversation patterns against the pricing scheme before you commit.
Key Takeaways
What every developer should understand about Voice Agent APIs:
A Voice Agent API coordinates the full STT → LLM → TTS loop, enabling stateful, turn-based conversations instead of one-shot audio tasks.
Latency is the main engineering constraint; the handoff from Speech-to-Text (STT) to the Large Language Model (LLM) is often the biggest bottleneck.
End-to-end streaming is critical. If any layer (STT, LLM, or TTS) batches requests, the delays compound quickly.
Most offerings fit three patterns: fully managed platforms like the Smallest.ai Voice Agent, modular component APIs, or speech-to-speech APIs, each with clear trade-offs.
Voice identity is a core product decision. A consistent, branded voice significantly impacts user trust and perceived quality.
Before choosing a provider, evaluate latency benchmarks, streaming support, voice customization options, and how pricing scales with usage.
Building Without the Latency Tax: Why the Stack You Choose Matters
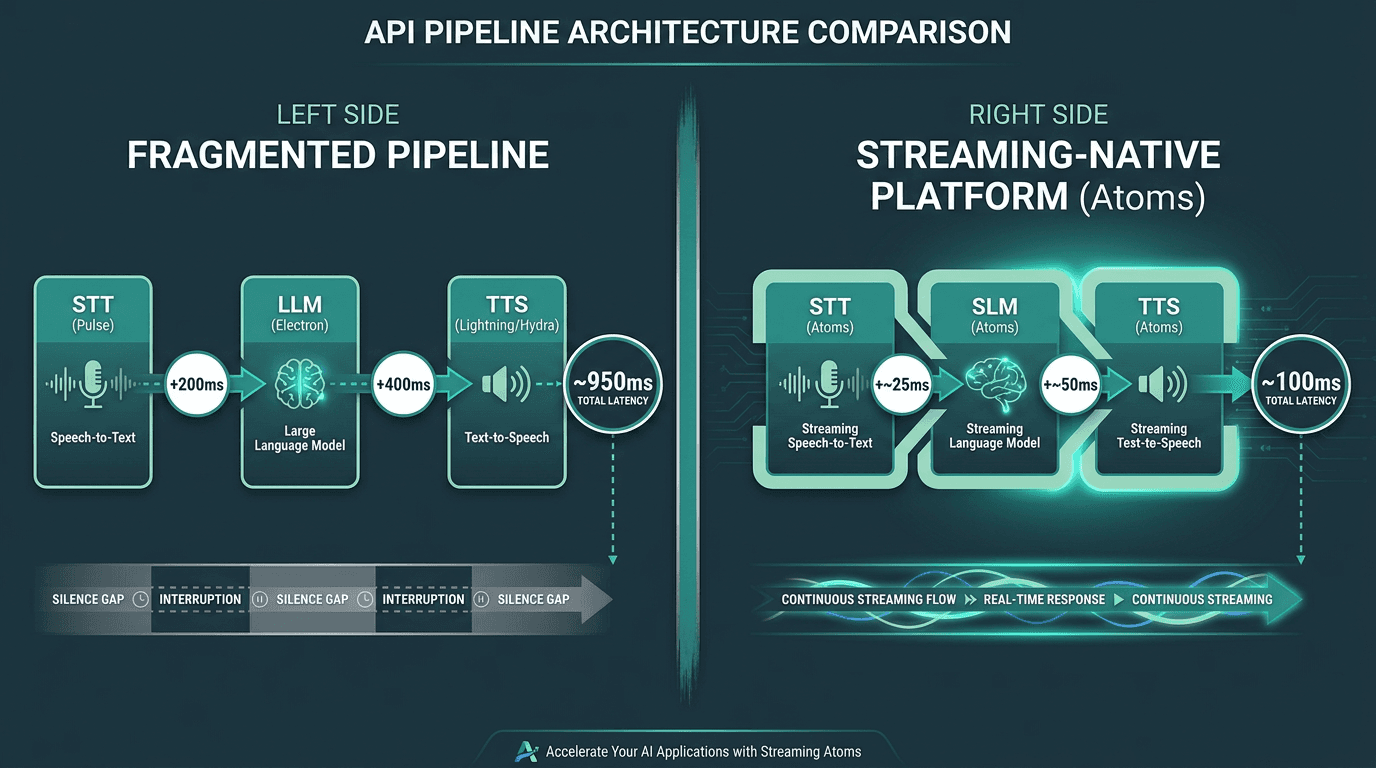
Latency compounds at every inter-service handoff. Tight integration reduces the tax at each stage.
Here is the pattern I see teams run into: they assemble a pipeline from individually strong components, run a quick demo, and it sounds fine. Then they test it like a real caller would (interruptions, uneven audio quality, longer turns) and the delays start stacking in ways that never showed up when each service was measured alone. STT adds 200ms. The model takes 400ms to first token. TTS needs another 150ms before playback starts. You are now close to a full second of silence before the caller hears anything, and that pause is enough to shatter the conversational feel.
Smallest.ai’s Atoms platform and Waves API are built to avoid that compounding effect. The stack is streaming-native end to end: Pulse for STT, Electron for conversational SLM, and Lightning or Hydra for synthesis. Because the components are designed to work together, rather than being separately optimized services stitched together at integration time, the inter-component latency is reduced by design, not patched over later. For developers who want production-grade voice agents without building orchestration from scratch, that means a clearer path to deployment without having to solve latency independently at every handoff.
If you are comparing stacks for a voice agent project, the Waves API provides developer-level access to the full pipeline, while the Atoms platform adds the orchestration layer on top. Smallest.ai's Voice Agents is the most direct place to see what is available and how it maps to your use case.
What’s the difference between a Voice Agent API and a text-to-speech API?
What latency should I plan for in a production voice agent pipeline?
Can a Voice Agent API give my product a custom branded voice?
Do I need to run STT, LLM, and TTS as separate services, or can one platform handle the whole pipeline?
Which industries are adopting voice agents fastest, and what does deployment look like in practice?