Vapi Alternatives in 2026: Pricing, Latency & Platform Comparison


Comparing the best Vapi alternatives in 2026 on latency, pricing, and architecture. Find the right voice agent platform for your production use case.
The AI voice agent market is no longer a niche experiment. The voice AI agent market is projected to reach $47.5 billion by 2034. Teams evaluating Vapi's alternatives are doing so under real production pressure: latency budgets, cost models, and reliability requirements that prototype-era tooling wasn't designed to handle.
This comparison is written for developers, product teams, and technical decision-makers who have already looked at Vapi and want a clear picture of what else is available before committing. What follows covers why Vapi's cost model tends to surprise teams at scale, which metrics actually determine production success, public pricing where available, plus the cost variables teams should verify before production , and how to match a platform to your specific build.
Why Are Teams Looking for Vapi Alternatives?
Vapi is a well-known voice orchestration layer. It handles the plumbing between your STT provider, LLM, and TTS provider, and for prototyping that job is done reasonably well. The friction appears when teams move to production.
Vapi's orchestration pricing starts at pay-as-you-go rates published on their site, but this requires you to bring your own STT, LLM, and TTS, each billed separately. Stack those layers and the real cost lands between $0.07 and $0.25 or more per minute depending on your choices. For a contact center running 100,000 minutes per month, the gap between the advertised rate and the actual bill is not a rounding error.
None of this makes Vapi a bad product. It makes it a product with a specific profile: flexible and developer-friendly for experimentation, but potentially expensive and variable at scale. If that profile doesn't match your requirements, the alternatives below deserve serious consideration. For a broader look at the orchestration landscape, the best voice AI orchestration alternatives piece covers the category in depth.
= The real per-minute cost of a voice agent stack often exceeds the orchestration headline rate by 2-5x.
What Should You Actually Evaluate in a Voice Agent Platform?
Most comparison posts default to feature checklists. The metrics that actually determine whether a platform survives contact with production are different, and worth being precise about before running through any shortlist.
Criterion | Why It Matters | What to Measure |
|---|---|---|
End-to-end latency | Drives perceived naturalness of conversation | Time from user utterance end to agent speech start (target: <500ms) |
Pricing model transparency | Determines true cost at scale | All-in per-minute cost including STT, LLM, TTS |
STT/TTS integration | Affects latency and vendor lock-in | Native vs. bring-your-own provider |
Concurrency limits | Determines scalability ceiling | Max simultaneous calls on base tier |
Telephony support | Required for phone-based use cases | SIP trunking, PSTN, WebRTC support |
Customization depth | Affects how well the agent fits your product | Prompt control, voice cloning, interrupt handling |
Latency deserves particular attention. At 1,500ms, a caller experiences a pause long enough to prompt them to repeat themselves or simply hang up. That's not a benchmark curiosity; it's a conversion metric for any inbound support or sales use case. The STT layer you pair with your platform is one of the highest-leverage decisions in the stack. The best speech-to-text APIs guide covers that component in detail if you're still working through that choice.
Which Platforms Are the Best Vapi Alternatives in 2026?
The platforms below represent a realistic shortlist for teams building production voice agents. Each has a distinct profile, and the goal here is to give you enough signal to match a platform to your actual requirements, not to declare a universal winner.
Smallest.ai
Smallest.ai voice agents take a different architectural approach from most orchestration-only platforms. Rather than acting as middleware connecting third-party STT, LLM, and TTS services, Smallest.ai builds the speech stack natively. The Lightning TTS engine, Pulse STT, and the Electron conversational model are all developed in-house, which means the latency budget isn't split across three separate API round trips. The Atoms platform handles agent orchestration on top of that native foundation.
For teams burned by the variable latency of assembled stacks, this architecture matters in practice. The Electron conversational small language model is optimized specifically for voice interaction patterns rather than general text generation, which shapes how naturally the agent handles interruptions, turn-taking, and short responses. Smallest.ai pricing reflects the all-in cost rather than a base rate that expands with add-ons.
Retell AI
Retell AI is a developer-focused orchestration platform with strong telephony support and a clean API surface. 2026 benchmarks place Vapi latency between 700-1,500ms and Retell at 600-800ms depending on configuration. Retell AI pricing starts at pay-as-you-go rates published on their site. It's a credible option for teams that want more cost predictability than Vapi while preserving flexibility in LLM choice.
Bland.ai
Bland.ai is built primarily for high-volume outbound calling. Its pricing model is straightforward, telephony is included without a separate SIP provider, and Bland.ai pricing is published on their site and is competitive at outbound scale. The trade-off is customization depth: teams running automated outbound campaigns will find it worth evaluating seriously, while teams building nuanced inbound agents may hit the ceiling faster than expected.
How Do the Platforms Compare on Pricing?
Platform | Architecture | Key Strength | Vendor Lock-in |
|---|---|---|---|
Smallest.ai | Native STT/TTS/LLM stack | Low latency, integrated stack | Low |
Vapi | Modular orchestration | Flexible provider choice | High |
Retell AI | Developer orchestration | Telephony focus | Medium |
Bland.ai | Outbound platform | High-volume calling | Medium |
The structural difference here is worth naming directly. Vapi's modular design gives flexibility but makes cost modeling difficult before you scale. Platforms with native stacks or flat per-minute rates let you project costs with confidence. If your stack includes Deepgram as an STT layer, the Deepgram alternatives guide is useful context for understanding where that component fits in your total cost picture.
What Most Teams Get Wrong When Switching Platforms
The most common mistake is optimizing for the wrong variable. Teams spend weeks comparing LLM integrations and voice selection while ignoring the latency profile of their STT provider or the interrupt handling behavior of the orchestration layer. In production, a 200ms improvement in STT response time is often more noticeable to callers than switching from one LLM to another.
A second mistake is evaluating platforms in isolation from telephony. If your use case involves actual phone calls, the platform needs to handle PSTN connectivity, SIP trunking, or carrier integration. Some platforms treat telephony as a first-class feature. Others treat it as an afterthought requiring a third-party SIP provider. That distinction changes your architecture significantly, and it's easy to miss until you're already mid-build.
The third mistake is underweighting voice quality in extended calls. Synthetic voices have improved dramatically, but there's still a meaningful gap between a voice that sounds natural in a 30-second demo and one that holds up across a 10-minute support call. Test voices on realistic call scripts, not showcase samples. For teams working through the full stack decision, choosing your 2026 voice agent stack walks through the component-level trade-offs in detail.
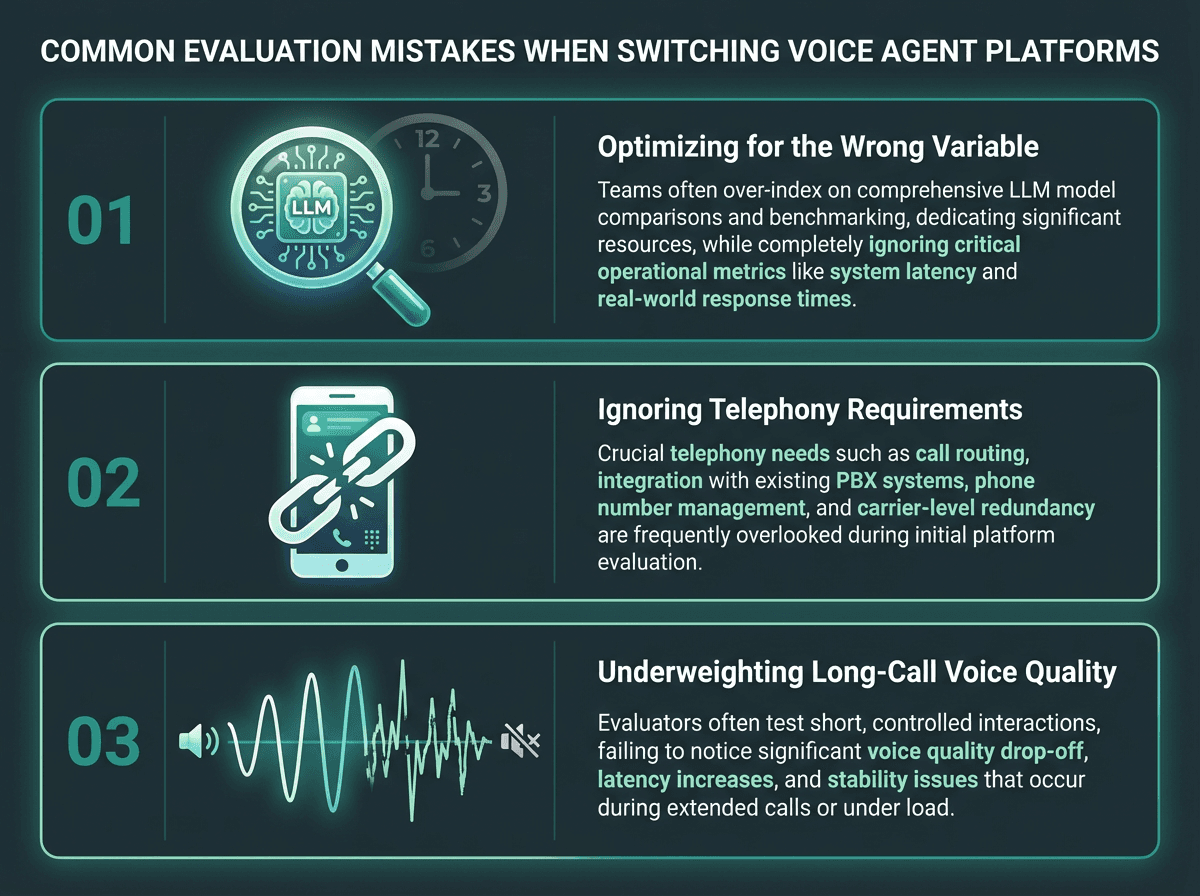
Latency, telephony, and long-call voice quality are the three most commonly underweighted factors.
How Do You Match a Platform to Your Use Case?
There's no universal answer, but the patterns are clear enough to be useful. High-volume outbound calling with simple scripts favors platforms with flat per-minute pricing and built-in telephony. Inbound support agents with complex conversational flows need strong interrupt handling, low latency, and voice cloning for brand consistency. Developer teams building custom voice products care most about clean APIs, solid documentation, and flexible LLM routing.
Quick matching guide by use case:
Outbound sales or appointment scheduling at scale: flat pricing, built-in telephony, and high concurrency limits matter most
Inbound customer support: prioritize latency under 500ms, interrupt handling, and voice naturalness across longer calls
Custom voice product or embedded agent: API flexibility, voice cloning, and native STT/TTS integration are the deciding factors
Rapid prototyping or proof of concept: modular platforms with pay-as-you-go pricing allow faster iteration without long-term commitment
Enterprise deployment with compliance requirements: data residency options, SLA guarantees, and dedicated infrastructure are non-negotiable
If you're building a production voice agent and want to see how a native stack performs against your specific requirements, book a demo of our voice agents to run a live evaluation with your actual use case rather than a curated script.
Key Takeaways
The voice agent platform market in 2026 offers real architectural choice, not just cosmetic differentiation. Vapi's modular model works well for experimentation and teams that want maximum flexibility in their LLM and voice provider choices. The cost and latency variability that comes with that model is a genuine trade-off at production scale, not a minor footnote buried in the pricing page.
Retell AI and Bland.ai each address specific parts of that trade-off: more predictable pricing and stronger built-in telephony, respectively. Smallest.ai addresses it at the architecture level by building the speech stack natively, removing the per-hop latency tax and the cost unpredictability of managing multiple vendor relationships. The Atoms platform, combined with Lightning TTS, Pulse STT, and the Electron conversational model, is built for teams that need production-grade performance without assembling and maintaining multiple vendor integrations. If that matches your requirements, it's worth putting through a real evaluation against your actual call scenarios.
What is the main difference between an orchestration platform and a native platform like Smallest.ai?
Are voice agent platforms free to use?
Which voice agent platform has the lowest latency?
Do I need a separate telephony provider to use these platforms?
How do I evaluate voice quality across platforms before committing?

