

Explore top Python packages for realistic Text-to-Speech (TTS). Compare pyttsx3, Coqui TTS, Mimic3, & Orca TTS for high-quality audio. Find your best solution!
Technology is making digital voices sound more human than ever. From virtual assistants answering your questions to audiobooks that sound like real narrators, machines can now speak with natural rhythm, tone, and emotion.
In fact, the global text-to-speech market is projected to reach $7.6 billion by 2026, driven by increasing demand in industries such as healthcare, customer service, and entertainment. But have you ever noticed how some AI voices sound robotic while others feel lifelike?
The difference lies in text-to-speech (TTS) technology. Some TTS solutions focus on speed, while others prioritize realism. Achieving the right balance is essential for developers and businesses seeking high-quality, natural-sounding speech.
Python has become the go-to programming language for TTS applications due to its simplicity, flexibility, and AI capabilities. With powerful libraries like TensorFlow, PyTorch, and WaveGlow, Python provides a solid foundation for building advanced TTS systems. These libraries make it easier to create voices that sound remarkably real, from the pitch to the subtle emotional nuances.
In this post, we'll explore the best Python packages for realistic text-to-speech, compare their strengths, and help you choose the right one for your needs.
Why is Python Text-to-Speech a Powerful Tool?
Whether you're building a voice assistant, audiobook narrator, or real-time AI conversation system, Python provides the tools to make it happen. Here’s why Python stands out for TTS applications:
Easy to learn and use: Python’s simple syntax makes it easy for beginners and experienced developers to implement TTS solutions quickly.
Wide range of libraries: Python offers offline and cloud-based TTS tools, from lightweight options like pyttsx3 to advanced AI-powered APIs like Smallest.ai Waves.
Seamless AI integration: Python works with deep learning frameworks like TensorFlow and PyTorch, enabling advanced voice synthesis with machine learning models.
Cross-platform compatibility: Python-based TTS applications work on Windows, macOS, Linux, and even embedded systems, ensuring broad usability.
Support for multiple languages and accents: Many Python TTS tools support multilingual speech synthesis, making it easier to create global applications.
Real-time processing capabilities: Some Python-based TTS solutions, like Smallest.ai Waves, generate speech in under 100 milliseconds, making them ideal for live applications.
Extensive API support: Cloud providers like Google Cloud, Amazon Polly, and Smallest.ai offer easy-to-use Python SDKs, simplifying TTS integration into applications.
With these advantages, Python remains one of the most powerful tools for developing high-quality, customizable, and scalable text-to-speech applications.
Now that you know the why, let us talk about some of the major python packages for realistic TTS solution.
Top Python Packages for Realistic Text-to-Speech Solutions
Several factors influence the choice of the right text-to-speech (TTS) package. Python offers both cloud-based AI solutions and open-source libraries, allowing developers to choose the best fit for their projects.
To compile this list, we evaluated each TTS package based on the following key factors:
Voice realism: How natural and expressive does the generated speech sound?
Speed and latency: Can it generate speech in real-time, or does it require processing time?
Ease of integration: How simple is it to implement within Python applications?
Scalability: Is it suitable for enterprise-level projects, or is it better for personal use?
Here are the best Python packages for realistic text-to-speech solutions, ranked based on these criteria.
1. Smallest.ai Waves
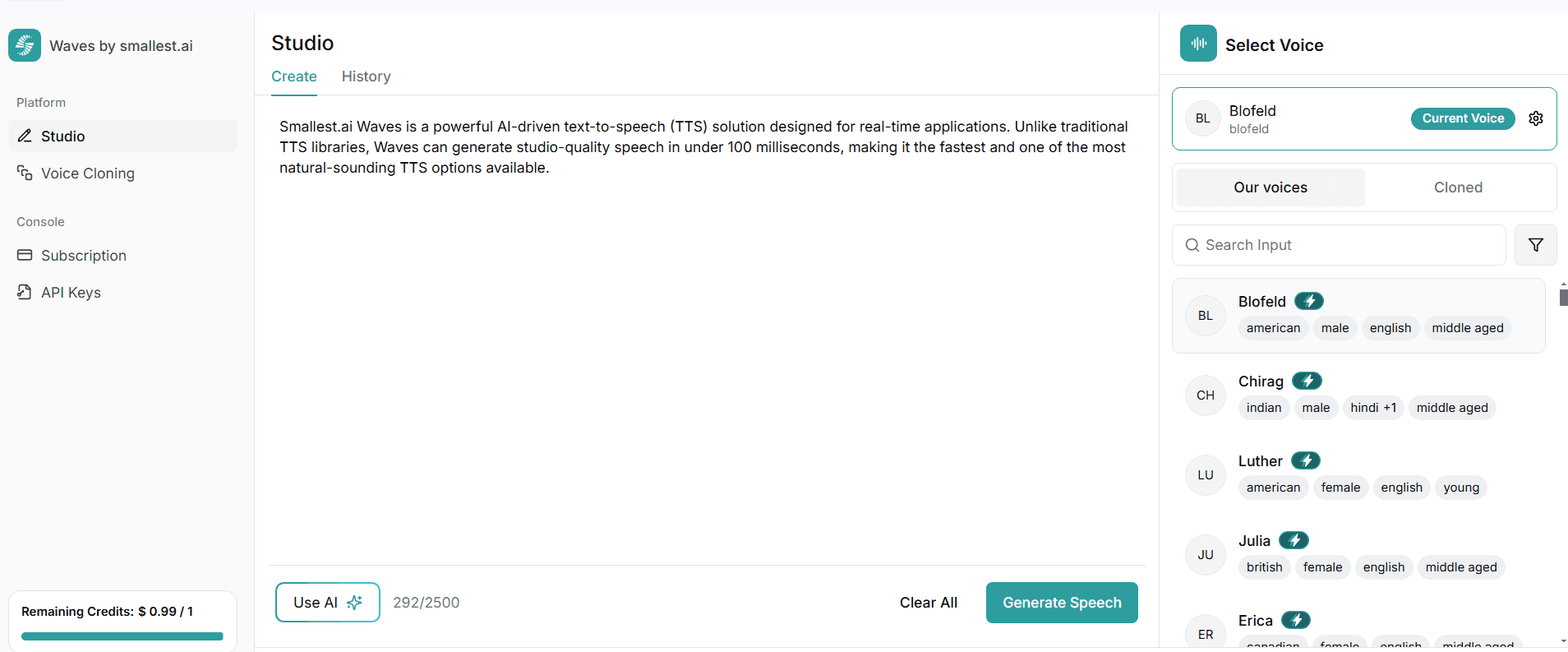
Best for: Real-time, ultra-realistic AI voices with low latency and instant voice cloning.
Smallest.ai Waves is a powerful AI-driven text-to-speech (TTS) solution designed for real-time applications. Unlike traditional TTS libraries, Waves can generate studio-quality speech in under 100 milliseconds, making it the fastest and most natural-sounding TTS option available.
It supports 30+ languages, multiple accents, and instant voice cloning, allowing users to create custom voices with just 5 seconds of audio input. Developers can integrate it easily using the Smallest.ai Python SDK, which supports both synchronous and asynchronous processing for flexible deployment.
Features:
Ultra-low latency: Generates real-time speech in under 100 milliseconds.
AI-powered voice cloning: Creates custom AI voices with just 5 seconds of audio.
Multi-language support: Provides 30+ languages and accents for global applications.
Flexible API integration: Offers sync and async methods for scalable applications.
LLM-to-speech conversion: Converts AI-generated text into realistic speech instantly.
2. pyttsx3
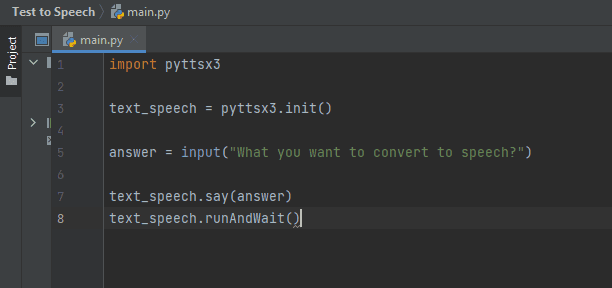
Best for: An Offline TTS Library, converting text to speech without an internet connection.
pyttsx3 is a lightweight, offline text-to-speech (TTS) library that works on Windows, macOS, and Linux. Unlike cloud-based TTS services, pyttsx3 does not require an internet connection, making it a reliable choice for applications that need local speech processing.
It supports multiple voice engines, such as SAPI5 (Windows), NSSpeechSynthesizer (macOS), and espeak (Linux). Developers can adjust the speech rate, volume, and voice properties to customize the output.
Features:
Works offline: Does not require internet access to function.
Multi-platform support: Runs on Windows, macOS, and Linux.
Adjustable speech settings: Allows control over speed, volume, and voice selection.
Easy integration: Uses simple Python commands for quick setup.
Open-source: Free to use and actively maintained by the community.
3. gTTS
Best for: Simple, cloud-based text-to-speech conversion using Google’s TTS API.
gTTS (Google Text-to-Speech) is a lightweight Python library that converts text into speech using Google’s online TTS service. It supports multiple languages and provides a simple way to generate MP3 audio files from text.
Since gTTS relies on an internet connection, it works well for basic applications but may not be ideal for real-time speech generation. Developers can control speech speed and language settings, making it useful for projects that require quick and easy voice synthesis.
Features:
Cloud-based processing: Uses Google’s TTS engine for speech generation.
Multi-language support: Converts text to speech in dozens of languages.
Simple implementation: Requires only a few lines of Python code to generate speech.
Customizable speech settings: Allows control over speed and language selection.
Outputs MP3 files: Saves speech as an audio file for playback or sharing.
4. Coqui TTS

Best for: Developers who need an open-source, customizable text-to-speech engine.
Coqui TTS is a powerful, open-source text-to-speech (TTS) library built on deep learning. It allows developers to train and fine-tune their own AI voices, making it highly customizable.
Coqui TTS supports multiple languages, voice cloning, and expressive speech synthesis, giving users full control over how their AI-generated speech sounds. However, since CoquiAI shut down in 2024, active maintenance is no longer available, which may affect long-term usability.
Features:
Open-source and trainable: Allows custom voice training and fine-tuning.
Voice cloning support: Clones voices with a few seconds of audio input.
Multi-language support: Generates speech in over 13 languages.
Deep learning integration: Works with PyTorch for AI-based speech synthesis.
Expressive speech synthesis: Provides control over tone, pitch, and speaking style.
5. larynx
Best for: Running text-to-speech models locally on low-power devices.
larynx is an offline, open-source text-to-speech (TTS) library designed for local speech synthesis. It is optimized for low-power devices, making it a great choice for edge computing applications like Raspberry Pi.
Unlike cloud-based TTS solutions, larynx runs entirely on local hardware, ensuring privacy and independence from internet connectivity. It supports multiple voices and SSML tags, allowing users to customize speech output, but its voice quality is not as advanced as AI-powered cloud solutions.
Features:
Works offline: Runs entirely on local hardware without internet access.
Optimized for edge devices: Works efficiently on low-power systems like Raspberry Pi.
Multi-voice support: Offers a variety of prebuilt voices.
SSML support: Allows speech customization using SSML tags.
Privacy-focused: Keeps data processing local, ensuring no cloud dependency.
6. Mimic TTS from Mycroft AI
Best for: Open-source, offline speech synthesis with customizable voices.
Mimic TTS from Mycroft AI is an open-source text-to-speech engine designed for offline use and voice assistant applications. It supports both pre-trained voices and custom voice training, making it a flexible option for developers who want complete control over speech synthesis.
Mimic TTS is optimized for low-latency performance and can run on local devices without an internet connection. While it provides decent speech quality, it may not sound as natural as AI-powered cloud solutions.
Features:
Works offline: Runs entirely on local hardware without internet access.
Open-source and customizable: Allows custom voice training for personalized speech synthesis.
Fast speech generation: Delivers low-latency performance for real-time applications.
Multi-platform support: Works on Windows, macOS, Linux, and embedded devices.
Designed for voice assistants: Developed as part of Mycroft AI's voice assistant ecosystem.
With top Python packages for TTS in mind, here are some real-world application of python TTS.
Real-World Applications of Python TTS
Python-powered text-to-speech (TTS) technology is revolutionizing how businesses and individuals interact with digital content. From voice assistants to automated customer support, TTS solutions are making applications more accessible, engaging, and efficient. Here are some of the most common real-world applications of Python-based TTS:
AI voice assistants: Powers smart speakers, virtual assistants, and chatbots, enabling them to communicate naturally with users.
Audiobooks and podcasts: Converts written content into high-quality speech, making books, articles, and blog posts more accessible and engaging.
E-learning and training modules: Provides spoken lessons and interactive learning materials, improving student engagement and comprehension.
Accessibility for visually impaired users: Reads text aloud for people with visual impairments, enabling them to navigate websites, apps, and documents with ease.
Language learning applications: Helps users learn new languages by providing accurate pronunciation and interactive speech training.
Content creation and video voiceovers: This tool generates natural-sounding voiceovers for YouTube videos, marketing content, and documentaries, reducing the need for human narrators.
Smart home and IoT devices: This product integrates with home automation systems, allowing users to receive spoken updates, alerts, and notifications from their devices.
Telecommunications and call centers: Uses AI-generated voices to handle automated calls, appointment reminders, and notifications.
With Python-based TTS solutions becoming more advanced and widely available, their applications will continue to expand, making AI-generated speech an essential tool across multiple industries.
Conclusion
Python has become the preferred language for text-to-speech (TTS) solutions, offering flexibility and powerful AI-driven speech synthesis. Whether you're developing AI assistants, audiobooks, or real-time voice applications, a reliable and high-quality TTS engine is essential for delivering natural and engaging speech.
For those looking for the most realistic, low-latency, and scalable TTS solution, Smallest.ai Waves stands out. It delivers ultra-realistic voices with real-time processing, ensuring seamless integration for interactive applications.
Unlike traditional TTS solutions that struggle with robotic tones or slow response times, Smallest.ai’s Waves generates studio-quality speech in under 100 milliseconds, making it ideal for real-time conversations, IVR systems, and AI-driven content creation.
Its near-instant voice cloning feature allows users to create AI-powered voices with just a few seconds of audio. Its support for 30+ languages makes it perfect for global applications. Developers can easily integrate it with its flexible Python SDK, which offers both synchronous and asynchronous processing for maximum scalability.
If you're ready to bring AI-generated speech to your projects, Smallest.ai Waves is the best tool to get started. Try Smallest.ai’s Waves today and experience the future of text-to-speech technology.
Frequently Asked Questions About Python Text-to-Speech
If you're new to TTS or looking for the best tool for your project, this FAQ section answers some of the most common questions about Python-based speech synthesis.
Q. What is the Best Python Text-to-Speech Package for Natural Voices?
A. The best Python TTS package for realistic, human-like voices depends on your needs. Smallest.ai Waves delivers studio-quality AI voices with real-time processing, making it perfect for AI assistants, content creation, and IVR systems.
If you prefer an open-source option, CoquiTTS allows custom voice training. However, it lacks the speed and expressiveness of AI-powered alternatives.
Q. Can Python Text-to-Speech Work Offline?
A. Yes, some Python-based TTS solutions work entirely offline. pyttsx3 and larynx allow you to generate speech without an internet connection, making them useful for local applications and privacy-focused projects. However, offline solutions typically produce less natural-sounding speech compared to cloud-based AI models.
Q. How Do I Integrate Text-to-Speech Into My Python Application?
A. Most Python TTS libraries provide easy-to-use APIs. For example, you can install Smallest.ai Waves by running:
pip install smallestai
Then, generate speech in just a few lines of code:
from smallest import Smallest
client = Smallest(api_key="YOUR_API_KEY")
client.synthesize("Hello, this is a test.", save_as="output.wav")
Other libraries, like gTTS and pyttsx3, also support basic text-to-speech conversion with simple function calls.
Q. What is the Difference Between Open-Source and Paid TTS Solutions?
Open-source TTS: Free to use, customizable, and often works offline. However, these tools may lack real-time processing, high-quality voices, or long-term maintenance.
Paid TTS solutions: Cloud-based and AI-driven, offering realistic voices, instant processing, and better scalability. Services like Smallest.ai Waves provide ultra-realistic speech synthesis, voice cloning, and multi-language support, making them ideal for business and commercial applications.
Q. Which Python Text-to-Speech Package is Best for Commercial Use?
A. For commercial applications, you need a scalable, high-performance TTS engine that delivers natural-sounding voices in real-time. Smallest.ai’s Waves is the best choice because it offers low-latency speech synthesis, high-quality AI voices, and flexible API integration. It is perfect for customer service automation, AI assistants, audiobooks, and content creation.
Q. Can Python Text-to-Speech Convert Large Text Files Into Speech?
A. Yes, most Python TTS libraries support processing large amounts of text. Smallest.ai Waves, for example, can handle long-form text input and generate high-quality speech output in real-time. Some offline tools like pyttsx3 and CoquiTTS can also process long text files.
Q. Is There a Python TTS Solution That Supports Multiple Languages?
A. Yes, many Python-based TTS solutions support multi-language speech synthesis. Smallest.ai Waves provides 30+ languages and multiple accents, making it ideal for global applications. Other cloud-based solutions, like gTTS, offer multi-language support.
Q. How Does Instant Voice Cloning Work in Python TTS?
A. Instant voice cloning allows you to create a digital voice model from a short audio sample. Smallest.ai Waves can generate a realistic AI voice with just 10 seconds of recorded speech, making it perfect for custom branding, AI narrators, and voice personalization.
Open-source alternatives like CoquiTTS also offer voice cloning but require longer training times and more computational power.
Q. What Is the Fastest Python TTS Solution for Real-Time Applications?
A. For real-time applications like AI chatbots, voice assistants, and IVR systems, Smallest.ai Waves is the fastest option, delivering speech output in under 100 milliseconds. Open-source models, like TortoiseTTS and CoquiTTS, can generate realistic voices, but they are much slower and unsuitable for live interactions.
Q. How Do I Choose the Right Python TTS Package for My Project?
A. Your choice depends on your needs:
If you need real-time AI-generated voices, Smallest.ai’s Waves is the best option.
If you need an offline solution, pyttsx3 or larynx are suitable but less advanced.
If you want open-source and customizable AI voices, CoquiTTS is a good choice, but it lacks real-time responsiveness.
If you need a simple, cloud-based tool, gTTS works well but requires internet access.
For the best balance of speed, quality, and flexibility, Smallest.ai Waves provides the most advanced AI-powered TTS solution available.
Try Smallest.ai Waves today and experience ultra-realistic, real-time speech synthesis.

