Unlocking Human-Level Real-Time Intelligence in Voice through
Asynchronous Input, Output Mechanisms and Continuous Latent Thinking
Introduction: Voice Is Real, Text Is Not
Voice is a physical signal. It exists in the real world as pressure waves propagating through air, captured by the ear and transduced into neural activity. It is continuous, analog, and fundamentally temporal: every syllable, every pause, every shift in pitch carries meaning that is inseparable from when it occurs. Voice is how humans evolved to communicate, negotiate, teach, and reason. It is the oldest and most natural interface for intelligence.
Text, by contrast, does not exist in the physical world. Text is a human invention, a discrete symbolic encoding system created to preserve speech across time and space. Critically, text is consumed through vision, not through audition. When you read a sentence, your eyes scan symbols on a surface; your visual cortex processes shapes and patterns. Text has no time domain. The word "hello" on a page does not take 400 milliseconds the way the spoken word does. It has no prosody, no emphasis, no emotional coloring. It is an abstraction, a lossy compression of the rich, continuous, temporally grounded signal that is voice.
All real physical signals are continuous and have an inherent time domain. Sound, light, touch, proprioception: these are the signals through which biological intelligence engages with the world. Any system that aspires to human-level conversational intelligence must treat voice as what it is: a real, continuous, temporal signal. It must not reduce voice to text, process the text, and then re-expand text back into voice. That pipeline discards the very properties (continuity, temporality, paralinguistic richness) that make voice the medium it is.
However, simply removing text by fusing intermediate layers to form a speech-to-speech model is not enough. We need to think backwards from how a human brain operates and build an architecture that is capable of behaving like humans do when they converse, i.e., passing the Turing test [Turing, 1950].
This thesis presents a positive case for a new class of voice architecture, asynchronous world models operating on compressed latent representations, as the path to building voice agents that can genuinely pass the Turing test in real-time spoken conversation. We begin by examining how humans process voice, identifying three concurrent capabilities (listening, thinking, and speaking, together with concurrent action) that define natural conversation. We then present Hydra, an architecture designed from first principles to replicate those capabilities. Finally, we explore how this paradigm points toward a future of efficient, adaptive intelligence.
Our position throughout is structure and scale, not scale alone: voice intelligence requires the scale that self-supervised learning over raw audio provides, but also the structure that cognitive science has shown humans actually use. An architecture that commits to scale alone pays a scaling tax to recover what is already known about conversation; an architecture that builds the structure in directly can be orders of magnitude smaller.
The scientific grounding for the claim that human conversation has structure at multiple computational levels is developed in detail in a companion paper [Smallest AI Research, 2026], which reviews the cognitive-science and neuroscience evidence from behavioral, electrophysiological, intracranial, and computational studies. The present paper takes that evidence as background and focuses on the architectural consequences for voice AI.
Related Work: The Evolution Toward Native Voice Architectures
Pipeline orchestration. The most widespread approach to voice agents composes separate, independently trained models into a sequential pipeline. An automatic speech recognition system such as Whisper [Radford et al., 2022] transcribes incoming audio into text. A large language model such as GPT-4 [OpenAI, 2023] or LLaMA [Touvron et al., 2023] processes the transcript and generates a text response. A text-to-speech engine synthesizes audio from the response text. A voice activity detection module determines when the user has stopped speaking so the pipeline can begin processing. The engineering effort in this paradigm is concentrated on latency reduction: streaming ASR, speculative decoding, and streaming TTS [Ren et al., 2020]. Regardless of how aggressively these optimizations are applied, the architecture enforces strict sequential dependencies that impose a hard floor on latency and destroy paralinguistic information at the ASR-to-text boundary.
Fused speech-to-speech models. The second generation of voice architectures attempts to address information loss by fusing the pipeline into a single model. Approaches like AudioPaLM [Rubenstein et al., 2023], SpeechGPT [Zhang et al., 2023], and Spirit-LM [Nguyen et al., 2024] remove terminal layers and connect speech encoders and decoders through shared intermediate representations, enabling transfer of emotional and prosodic information between stages. This fusion improves paralinguistic fidelity, but the fundamental processing model remains synchronous and sequential. The system still waits for the user to finish speaking, processes the complete utterance, and then generates a complete response. The interaction pattern is still turn-based and the system is still deaf while it is thinking or speaking.
The shared heritage: offline models in an online world. Both generations share a common genealogy: they descend from models designed for offline, batch processing of text [Vaswani et al., 2017, Brown et al., 2020]. Large language models were trained on static corpora with no temporal dimension. Speech recognition models were trained to transcribe completed utterances. Speech synthesis models were trained to render complete sentences. When these models are repurposed for real-time voice interaction, they are being asked to operate in a paradigm fundamentally different from the one they were designed for. The insight motivating the next generation is not that these systems are failures (they have produced commercially useful products and advanced the state of the art) but that human conversation has specific properties that require a fundamentally different architectural foundation.
The emerging world-model paradigm. In parallel with voice AI, the broader machine learning community has increasingly recognized the power of world models: systems that maintain compressed internal representations of their environment and reason over those representations rather than over raw sensory data. From the foundational work of Ha and Schmidhuber [2018] on world models for reinforcement learning to the Dreamer architectures of Hafner et al. [2020, 2023] and LeCun's vision for autonomous machine intelligence based on world models [LeCun, 2022], the pattern is consistent: systems that reason over latent representations achieve superior generalization, efficiency, and adaptability compared to systems that operate on raw observations. Hydra extends this paradigm to voice.
What Makes Human Conversation Human
To build a voice agent that passes the Turing test, we must understand precisely what it needs to replicate. Human conversational voice processing is defined by three concurrent capabilities that operate simultaneously and independently - Thinking while Listening, Acting while Listening and Speaking while Listening [Pickering and Garrod, 2004, Levinson, 2016]. Together, they produce the fluid, responsive, emotionally attuned experience that we recognize as natural conversation. The cognitive-science evidence for these capabilities, together with the broader claim that human conversation is organized around discrete structures at seven computational levels from sub-lexical units to speaker mental states, is reviewed in the companion paper [Smallest AI Research, 2026].
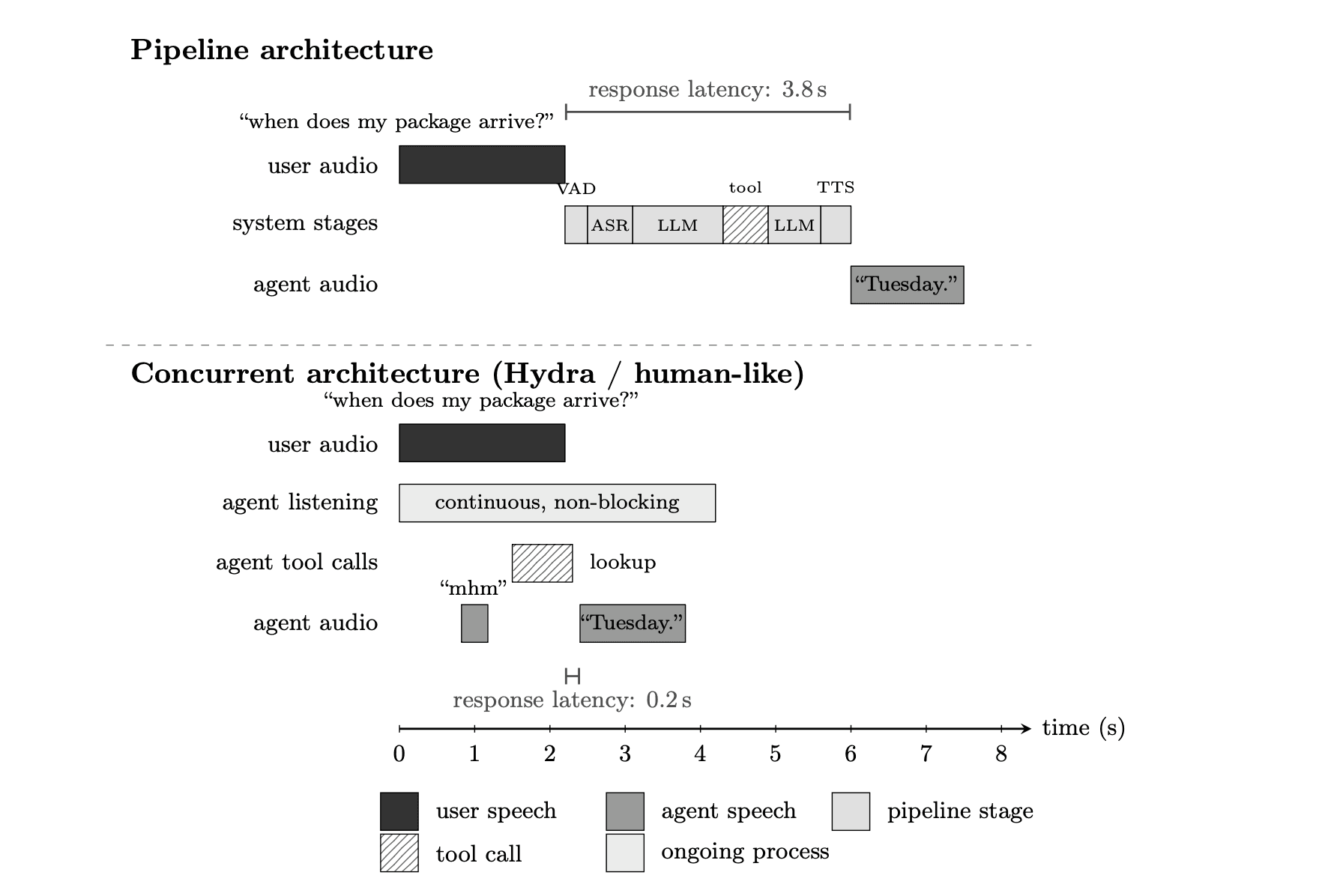
Figure 1: Pipeline architecture versus concurrent architecture on the same user query. Both panels share the same time axis and the same exchange: the user asks a package-tracking question and the agent responds. Top panel: a pipeline architecture processes the exchange as a strict sequence of stages (voice-activity detection, automatic speech recognition, language-model inference, tool call, language-model generation, text-to-speech), each waiting for the previous to complete.
The agent’s reply begins 3.8 seconds after the user’s question ends. Bottom panel: concurrent architecture operates as a set of non-blocking processes over a shared latent state. Listening runs continuously; a backchannel (“mhm”) is produced mid-utterance; the tool call fires before the user has finished speaking, because inference over the latent state has already recognized the referent and the intent; the reply begins roughly 200 milliseconds after the user’s last word.
Total time to response onset is 0.2 seconds, an order of magnitude faster, and the interaction pattern is structurally equivalent to human conversation. The architectural properties that make the bottom panel possible (concurrent execution, shared latent state, bidirectional inference) are developed in Section 4 and illustrated in Figure 2.
Thinking while listening. A human listener begins processing, interpreting, and formulating responses the moment speech arrives, not after the speaker finishes [Pickering and Garrod, 2004]. Comprehension is a continuous, streaming process that runs in parallel with auditory input. By the time a speaker reaches the end of a sentence, the listener has already anticipated its trajectory, drawn inferences, and often formulated a response. This concurrent cognition is what enables the sub-second response latencies that characterize natural conversation. An architecture that supports thinking while listening must decouple its reasoning process from its input process entirely.
Acting while listening. Humans routinely take actions (looking things up, taking notes, performing calculations) while continuing to listen [Salvucci and Taatgen, 2008]. A customer support agent receiving a caller's account number begins searching the system the moment they hear the first few digits, without pausing their attention to the caller's speech. An architecture that supports acting while listening must invoke external tools and process their results without suspending its listening or reasoning processes. Tool calls must be non-blocking.
Speaking while listening: full-duplex communication. Human conversation is full-duplex: speech production and reception occur simultaneously [Levinson, 2016, Sacks et al., 1974]. Backchanneling, the continuous stream of "mmhmm," "right," "yeah," signals engagement without interrupting the speaker. Overlapping speech, interruptions, and collaborative sentence completion are normal features of conversation. Input and output are not gated on each other; they are asynchronous. Every current voice architecture operates in half-duplex mode, and this alone is sufficient to fail the Turing test, because half-duplex conversation is immediately identifiable as non-human.
Hydra: Asynchronous Voice Intelligence Through World Models
Hydra is an architecture developed at Smallest AI that satisfies all three requirements by design. It is not an optimization of existing approaches but a new foundation, built from the ground up around the insight that voice intelligence requires asynchronous, concurrent processing over compressed representations.
Figure 2 illustrates Hydra’s architecture.

Figure 2: Hydra’s asynchronous architecture, organised around a conversational physics engine. The central component is a structured latent state that represents the conversation as a physical scene: who is speaking, what was said, what each speaker believes, what is in the common ground, what dialogue acts are in play, and where in the turn-taking cycle the conversation currently sits.
The analogy is to game physics engines, which maintain a world state of objects,velocities, and forces and run forward simulation continuously regardless of what the renderer or the input handler is doing; here the engine maintains a conversational world state and runs predictive simulation continuously regardless of what the listening, speaking, or tool-calling subsystems are doing. The four processes (listening, thinking, speaking, tool calls) operate as independent, simultaneously executing loops that read from and write to the shared engine state through well-defined interfaces. There is no pipeline ordering between them and none blocks anyother.
The cognitive-science evidence that human conversational reasoning operates as exactly this kind of structured, bidirectional, generative engine is reviewed in the companion paper
Asynchronous process architecture. Hydra's core innovation is architectural: listening, thinking, speaking, and tool-calling operate as independent, simultaneously executing processes that communicate through shared latent state. There is no pipeline, no sequential dependency, and no turn-based interaction model. The listening process continuously ingests audio and updates the shared latent state. The thinking process continuously reasons over that state, regardless of whether listening is active. The speaking process generates output audio from the reasoning state, regardless of whether new input is arriving. Tool-calling processes execute in the background and feed results back into the shared state without blocking any other process. This asynchronous design directly mirrors the three properties of human conversation. The system thinks while listening because thinking and listening are independent processes. It acts while listening because tool calls are non-blocking. It speaks while listening because speech production and reception are decoupled. The result is a system whose conversational dynamics are, for the first time, structurally equivalent to those of a human conversant.
Latent-space world model. Hydra is, at its core, a world model for voice. As continuous audio input arrives, Hydra compresses it into a dense latent space that preserves the full richness of the speech signal: not just lexical content, but prosody, emotion, hesitation patterns, speaking rate, emphasis, and micro-timing. This latent representation is the system's internal model of the conversational world: a continuously updated, compressed representation of everything that is happening in the dialogue. An autoregressive model then operates over this latent space, predicting and generating the next states of the conversation. Because the intelligence layer reasons over compact latent representations rather than high-dimensional discrete tokens, Hydra achieves extraordinary parameter efficiency. The same level of conversational capability that would require hundreds of billions of parameters in a token-based language model can be achieved in a latent-space world model that is one hundred to one thousand times smaller. This is not a marginal efficiency gain; it is an architectural shift that changes the economics and deployment landscape of voice AI entirely.
Why latent space enables true voice understanding. The choice to operate on latent representations is not merely an efficiency optimization: it is the key to genuine voice understanding. When voice is transcribed into text, the transcription discards the majority of the information carried by the speech signal. Two utterances with identical words but different prosody, timing, and emotional tone will produce the same transcript. A text-based model literally cannot tell them apart. A latent-space world model preserves this information because the latent representation is derived from the raw audio, not from a text intermediary. The model reasons over a representation that captures what was said, how it was said, and when it was said: the full communicative act, not just its textual shadow. The latent space is not unstructured; it is a learned compression that preserves the categorical structure of conversation (phonetic units, prosodic categories, dialogue acts, turn-taking events, common-ground state) that cognitive science has independently identified at the computational level [Smallest AI Research, 2026].
Two Approaches to Intelligence: Store Everything or Compress and Adapt
The central design question is the relationship between structure and scale. Modern large language models represent one answer: commit to scale, store everything in parameters, and trust that the structure of the world will be recovered as an emergent property of sufficient data and sufficient compute. Hydra represents a different answer: commit to both. Build the structure in, use scale where it earns its keep (the perceptual layer, the latent compression, the predictive dynamics), and let the structure do the work that scale alone cannot do efficiently. This is structure and scale, not scale alone, and it is the design principle on which Hydra is built.
Figure 3 positions Hydra in the structure-and-scale design space relative to current alternatives.

Figure 3: The structure-and-scale design space for voice and conversational AI systems. The horizontal axis represents scale (parameter count, training-data volume); the vertical axis represents the degree of designed-in structural inductive bias (the extent to which the system’s architecture commits to representations that match what cognitive science attributes to human conversational reasoning). Contemporary foundation models occupy the bottom-right quadrant, large scale, low designed-in structure, with whatever conversational structure exists left to be recovered as an emergent property of training. Hydra occupies the upper-left region: the conversational physics engine of Figure 2 is structurally committed by design, and scale is concentrate where it earns its keep (the perceptual layer, the latent compression, the predictive dynamics) rather than spread across the entire system. The dashed arrows show the two design paths from the same starting point. This is the position summarised as structure and scale, not scale alone:not a rejection of scale but a claim that structure must accompany it.
Approach one: store everything in the model. The first approach, exemplified by contemporary large language models [OpenAI, 2023, Touvron et al., 2023, Vaswani et al., 2017, Brown et al., 2020], is to train on real-world tokens and store as much information as possible in the model's parameters. The model memorizes what has happened in the world (facts, patterns, procedures, relationships) and encodes all of this in its weights. The advantage of this approach is comprehensiveness: a sufficiently large model trained on a sufficiently large corpus can answer questions about an extraordinary range of topics. When asked, for example, what are the exact dimensions of an iPhone, an LLM can probably give an accurate answer if this information was present in the training data. The disadvantage is fundamental: the world generates new information every second, and no fixed-size parameter space can keep pace. If you keep storing all information in the model layers, you will eventually run out of space. Scaling the model to accommodate more knowledge also scales the computational cost of every inference, even when the vast majority of stored knowledge is irrelevant to the task at hand.
Approach two: compress and remember what matters. The second approach, the one Hydra embodies, involves (a) compressing information and reasoning on only what is required to predict the state of the world and perform the distribution of tasks at hand more efficiently; and (b) remembering only what is relevant to the tasks in hand and relying on long-term memory for everything else. With this, rather than memorizing the world in its entirety, the model learns to build compressed representations that capture the essential structure and dynamics of its input domain. It stores the logic of how to reason, how to infer, how to predict, but not the totality of facts about the world. This closely mimics the human brain. A software engineer would probably not remember the rate of reaction for hydrogen and oxygen; however, given that a software engineer comes from a STEM background, he or she would be able to, if motivated, reference the right chemistry textbook from school and answer the question. Another example is when asked about the exact dimensions of the iPhone, as in the height, width, and length: most humans would not be able to answer, however they can, if motivated, get a measuring tape and find out. Storing these facts inside the brain is inefficient and unnecessary for the daily routine a human has. Both approaches to intelligence have legitimate advantages, and one can argue the tradeoffs in both directions. However, what is scalable and closer to human intelligence in the long term is clear: you have to train on compressed representations and you have to remember only what is relevant, because there is infinite information being generated in the world with every passing second and you cannot remember everything. This is a specific instance of the more general position defended in the companion paper [Smallest AI Research, 2026]: structure and scale, not scale alone. The most difficult challenge then is to answer: what to remember and what to forget?
Separation of intelligence from memory. This insight leads naturally to a principle we call the separation of intelligence from memory. Hydra's intelligence layers are dedicated to logic: how to reason, how to infer, how to conduct a conversation, how to recognize when external information is needed, and how to retrieve it. Factual knowledge lives in an external memory system (retrieval-augmented databases, tool APIs, domain-specific knowledge bases) that the model accesses through learned tool-calling behavior. The intelligence knows how to think; the memory knows what to think about. This separation is what makes compact, efficient models not just possible but architecturally optimal.
Inference-Time Adaptation and the Path to Specialization
The separation of intelligence from memory raises a natural question: how does Hydra learn and adapt during deployment? This is where one of Hydra's most distinctive properties emerges.
Time-series loss on latents. Because Hydra operates as a world model over compressed latent representations, its core operation is prediction: given the current latent state, predict the next state of the conversational world. The latents are essentially a predictive view of the world, a compressed forecast of what will come next in the conversation. When the prediction is wrong, when the actual next state diverges from the predicted state, Hydra can apply a time-series loss function over the latent space to measure and correct the discrepancy. This is a fundamentally different learning signal from the token-level cross-entropy loss used in conventional language models. A time-series loss over latents captures the temporal dynamics of conversation (the ebb and flow of topics, the evolution of emotional states, the rhythm of turn-taking) at a level of abstraction that is both richer and more compact than token-level prediction. It enables Hydra to learn from the structure of real-time interaction in a way that text-based models architecturally cannot.
Inference-time learning. The time-series loss on latents opens the door to inference-time learning: the ability to adapt and improve during deployment, in real time. As Hydra processes real conversations, its predictive model of the world is continuously tested against reality. When predictions fail, the system adjusts its internal weights to improve future predictions. This is the same basic mechanism through which humans learn from conversation; we form expectations, observe outcomes, and update our models of the world accordingly [Clark, 2013]. While inference-time learning is not fully solved, we have seen early results that are encouraging, and we believe strongly that the future lies in time-series loss functions over latent representations. This mechanism is what enables a true separation of intelligence from memory: the intelligence layers learn to predict and reason, while the memory system provides the facts and context needed for specific predictions. Inference-time learning allows Hydra to remember what is important for the task at hand and let go of what is not.
Artificial Special Intelligence. The combination of asynchronous architecture, latent-space reasoning, intelligence-memory separation, and inference-time learning leads to a new capability we term Artificial Special Intelligence (ASI). By special intelligence, we do not mean models that are specialized, static systems fine-tuned for a narrow domain. We mean models that have the ability to quickly specialize in real time, and for which specialization is highly efficient. This is efficient intelligence, in the same way that human intelligence is efficient. Consider a concrete example: a voice agent deployed for customer support at a financial enterprise. The agent arrives with general-purpose reasoning capabilities and access to domain-relevant tools and knowledge bases. As it processes real interactions, it rapidly learns which patterns, facts, and tool-calling strategies are most relevant to its operating domain. Within a small number of interaction cycles, the model becomes a specialist, not because someone fine-tuned it, but because it learned to specialize itself through use. Irrelevant information is deprioritized. The model becomes efficient at its particular task. This is the sense in which small models become powerful. A compact reasoning core that can quickly and efficiently adapt to any deployment context is architecturally superior to a massive model that dilutes its capacity across every domain. The measure of capability is not total parameter count but the efficiency and adaptability of the reasoning core [Lake et al., 2017].
Hydra, the Future of Voice
We can now bring together the full picture of how Hydra's architecture points toward a new era in voice AI, and more broadly, in intelligence itself.
Voice is the native modality of human intelligence: a real, continuous, temporally grounded physical signal. Current approaches to voice AI, both pipeline orchestration and fused speech-to-speech models, treat voice as a wrapper around text processing, inheriting the sequential, turn-based, half-duplex constraints of their text-centric heritage. These systems have been valuable and have advanced the field, but they cannot replicate the concurrent, asynchronous, full-duplex nature of human conversation.
Hydra provides a fundamentally different foundation. By treating voice as the native modality, compressing it into a latent space, and reasoning over those compressed representations with an asynchronous architecture where listening, thinking, speaking, and acting are all independent processes, Hydra achieves conversational dynamics that are structurally equivalent to human conversation for the first time.
The latent-space world model at Hydra's core enables parameter efficiency gains of one hundred to one thousand times over token-based models, making real-time voice intelligence deployable on edge hardware and consumer GPUs. The separation of intelligence from memory means that the model's capabilities scale with its memory system, not with its parameter count. And inference-time learning through time-series loss on latents enables rapid, efficient specialization, the foundation for Artificial Special Intelligence.
While inference-time learning on latent representations is an active area of research, and many open questions remain about the dynamics of adaptation, the stability of learned representations, and the boundaries of what can be learned at inference time versus what must be learned during training, we have seen early results that validate the direction, and we believe this is the future of efficient intelligence: compact reasoning cores that learn to think, access what they need to know, and adapt to the task at hand in real time. The path to passing the Turing test in real-time voice does not run through ever-larger models or ever-faster pipelines. It runs through architectures that mirror how intelligence actually works: concurrent, asynchronous, temporally grounded, and built on the right structural foundation. This is structure and scale, not scale alone; it is what Hydra is, and it is where voice AI is going.
Future Directions
Benchmarking Artificial Special Intelligence. Traditional benchmarks measure static capabilities on fixed tasks. Artificial Special Intelligence requires new evaluation methodologies that measure adaptation speed: how quickly a model specializes to a new domain, how much performance improves after N real interactions, how gracefully it handles domain drift, and how efficiently it forgets irrelevant information. Developing these benchmarks is critical for tracking progress and guiding architectural decisions.
Memory architecture and tool integration. The intelligence-memory separation requires sophisticated memory architectures that support efficient retrieval, graceful degradation under adversarial queries, and tight integration with inference-time learning dynamics. Research into retrieval strategies, memory indexing, update mechanisms, and the memory-reasoning interface is an essential companion to advances in the core model architecture.
A Turing test evaluation protocol. The field needs a rigorous evaluation protocol specifically designed for real-time voice interaction. Existing Turing test formulations target text-based dialogue [Turing, 1950] and do not capture the temporal, prosodic, and paralinguistic dimensions that are central to voice. A voice-specific protocol must evaluate response timing, emotional appropriateness, interruption handling, backchanneling behavior, and the naturalness of turn dynamics alongside content quality.
Measuring end-to-end business process automation. Ultimately, the practical test of voice AI is whether it can fully automate end-to-end business processes that are currently handled by human agents over voice. Customer support, sales, scheduling, triage, onboarding, compliance: these are domains where a voice agent must not only converse naturally but also execute complex workflows involving tool calls, system integrations, decision trees, and regulatory constraints. Measuring whether AI can completely automate these processes, from first contact through resolution, with no human intervention, is the definitive real-world benchmark for the capabilities described in this thesis.
References
Brown, T. B., et al. (2020). Language models are few-shot learners. Advances in Neural Information Processing Systems, 33.
Clark, A. (2013). Whatever next? Predictive brains, situated agents, and the future of cognitive science. Behavioral and Brain Sciences, 36(3), 181–204.
Ha, D., and Schmidhuber, J. (2018). World models. Advances in Neural Information Processing Systems, 31. arXiv:1803.10122.
Hafner, D., Lillicrap, T., Ba, J., and Norouzi, M. (2020). Dream to control: Learning behaviors by latent imagination. International Conference on Learning Representations 2020.
Hafner, D., et al. (2023). Mastering diverse domains through world models. arXiv:2301.04104.
Lake, B. M., Ullman, T. D., Tenenbaum, J. B., and Gershman, S. J. (2017). Building machines that learn and think like people. Behavioral and Brain Sciences, 40, e253.
LeCun, Y. (2022). A path towards autonomous machine intelligence. OpenReview preprint.
Levinson, S. C. (2016). Turn-taking in human communication: Origins and implications for language processing. Trends in Cognitive Sciences, 20(1), 6–14.
Nguyen, T. A., et al. (2024). Spirit-LM: Interleaved spoken and written language model. arXiv:2402.05755.
OpenAI. (2023). GPT-4 technical report. arXiv:2303.08774.
Pickering, M. J., and Garrod, S. (2004). Toward a mechanistic psychology of dialogue. Behavioral and Brain Sciences, 27(2), 169–190.
Radford, A., Kim, J. W., Xu, T., Brockman, G., McLeavey, C., and Sutskever, I. (2022). Robust speech recognition via large-scale weak supervision. arXiv:2212.04356.
Ren, Y., et al. (2020). FastSpeech 2: Fast and high-quality end-to-end text to speech. arXiv:2006.04558.
Rubenstein, P. K., et al. (2023). AudioPaLM: A large language model that can speak and listen. arXiv:2306.12925.
Sacks, H., Schegloff, E. A., and Jefferson, G. (1974). A simplest systematics for the organization of turn-taking for conversation. Language, 50(4), 696–735.
Salvucci, D. D., and Taatgen, N. A. (2008). Threaded cognition: An integrated theory of concurrent multitasking. Psychological Review, 115(1), 101–130.
Smallest AI Research (2026). The conversation engine: A position on symbolic world models for spoken dialogue. Companion paper.
Touvron, H., et al. (2023). LLaMA: Open and efficient foundation language models. arXiv:2302.13971.
Turing, A. M. (1950). Computing machinery and intelligence. Mind, 59(236), 433–460.
Vaswani, A., et al. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30.
Zhang, D., et al. (2023). SpeechGPT: Empowering large language models with intrinsic cross-modal conversational abilities. arXiv:2305.11000.