Rewriting TTS Inference Economics: Lightning V2 on Tenstorrent Achieves 4× Lower Cost Than NVIDIA L40S


The world’s first TTS model to deliver high-quality speech synthesis under joint BlockFloat8 quantization and reduced-precision arithmetic.
Key Highlights
4× lower on-prem inference cost vs NVIDIA L40S
~3.6× higher effective compute throughput at the same system cost, enabling ~4× higher concurrency
95%+ of layers running in LoFi computational fidelity without measurable audio degradation
80%+ of the model deployed in BlockFloat8 (BFP8)
~2× model size reduction via BFP8
Zero audible artifacts despite aggressive numerical optimization
Lightning V2 is the world’s first TTS model to combine computational fidelity and BlockFloat8 at production audio quality
Why Text-to-Speech Is More Numerically Fragile Than LLMs or Image Models
Text-to-Speech is fundamentally more numerically fragile than LLMs because it generates a continuous waveform, not discrete tokens. In language models, small quantization errors perturb probability distributions — the next token might change, yet the output often remains coherent due to natural reset points at token boundaries. In TTS, however, every numerical value directly contributes to audible signal energy. There is no boundary to absorb error. A small perturbation does not merely shift probabilities — it alters phase, harmonic structure, and waveform continuity. What is statistically minor in an LLM can become perceptually obvious in audio.
Speech also spans a wide dynamic range within milliseconds — from low-energy fricatives to high-energy vowels and rapid transients. When precision is reduced (e.g., with BlockFloat8 or LoFi compute), small numerical deviations can collapse low-energy phonemes, introduce background hiss, distort timbre, or cause pitch instability. Quantization error is not averaged out; it manifests as structured acoustic artifacts. In speech models, error affects perception — and the human auditory system is far less forgiving.
When Metrics Lie: Our PCC Observations
One of the most surprising observations during experimentation was around PCC (Pearson Correlation Coefficient), often treated as a gold-standard similarity metric.
When comparing the PyTorch model running on the NVIDIA L40S against CPU (AMD EPYC 7352 24-Core Processor), the end-to-end PCC was only 0.72, with identical inputs. Despite the low PCC (so low that it is considered mismatched) the audios were identical and good.
This made it challenging when porting onto tenstorrent without a reliable correctness metric:
For example, In one of the layer:
PCC was extremely high
Relative error was very small
PCC was so high that it rounded to 1.0
Yet that same layer caused audible output breakage.
Pinpointing this required over a month of investigation. The initial suspicion was on layers with lower PCC values. Ironically, the problematic layer appeared numerically “perfect” by standard metrics.
This highlights a critical insight:
Traditional numerical similarity metrics are not always reliable indicators of perceptual audio quality.
Architectural Constraints Unique to TTS
Some layer structures are inherent to modern TTS architectures.
Altering them:
Introduces robotic voice effects
Causes harmonic instability
Produces subtle but unacceptable artifacts
Certain precision requirements we encountered would be virtually unheard of in the LLM world. What is acceptable drift in language modeling becomes catastrophic in waveform generation.
Why This Makes BlockFloat8 + LoFi Extremely Challenging
For these reasons, aggressively applying BlockFloat8 and LoFi compute across a TTS pipeline is significantly more challenging than doing so for LLMs or image models.
Achieving:
95%+ LoFi layer coverage
80%+ BlockFloat8 adoption
No audible artifacts
required:
Architectural co-design
Selective precision retention
Custom kernel implementations
Layer-wise experimentation
Perceptual validation beyond standard metrics
TTS is numerically fragile because it generates a continuous, perceptually sensitive signal through iterative refinement. Small perturbations compound over time and manifest directly in the waveform.
That is why this optimization problem is fundamentally harder than it appears.
Hardware-Level Leverage: Why Tenstorrent Matters
Nvidia GPUs are built around massively parallel Streaming Multiprocessors (SMs). While extremely powerful for throughput workloads, SMs operate largely as independent execution units. When data produced by one SM is needed by another, it typically must traverse shared memory hierarchies and often round-trip through global memory.
This model works well for large batch workloads, but it introduces inefficiencies for single-sample TTS, where latency and memory movement dominate.
The Memory Movement Problem
In conventional GPU execution:
Multiple compute units may fetch overlapping weight tiles
Intermediate activations frequently spill to global memory
Layer transitions often require reloading data from DRAM
Even with high-bandwidth memory (HBM), DRAM access remains:
Energy-expensive
Latency-heavy
A dominant contributor to inference cost
High bandwidth does not eliminate memory movement- it only makes it less painful.
For single-stream Real-time TTS inference, you cannot rely on batching to amortize this cost. You pay the full memory latency every time.
How Tenstorrent Changes the Equation
Tenstorrent’s architecture introduces a Network-on-Chip (NoC) connecting compute cores directly, alongside large distributed SRAM.
This enables:
Direct core-to-core data movement without DRAM round-trips
Multicasting of weight tiles- a chunk of weights can be fetched once and broadcast across cores
Reduced redundant memory fetches
Lower power consumption due to minimized global memory traffic
In a typical matmul, instead of multiple units independently fetching the same weight block from DRAM, the block is fetched once and distributed efficiently across cores.
Memory movement - not raw FLOPs- is often the true bottleneck in inference. The NoC + SRAM design directly attacks this bottleneck.
Native BlockFloat8 Support at 40× Lower Hardware Cost
BlockFloat8 support exists in modern high-end GPU architectures, but it typically requires premium hardware tiers. For example, NVIDIA’s Blackwell-class GPUs with native FP8 capability are positioned in the ~$40,000 range per accelerator.
In contrast, Tenstorrent enables efficient BlockFloat8 execution on hardware in the ~$1,000 class.
That is roughly a 40× difference in hardware acquisition cost for enabling low-precision compute.
This fundamentally changes the cost-performance equation.
BlockFloat8 is not merely available — it becomes economically viable for real-time inference, including smaller and mid-sized TTS models where premium accelerator pricing cannot be justified.
When BFP8 is affordable at the hardware level, aggressive numerical optimization becomes deployable -not just theoretical.
Measured Results
Hardware | Cost | concurrency | Latency (ms) | Cost gain |
L40s | $9000 | 3 | 300 | 1x |
P150 | $1400 | 1 | 250 | 2.6x |
P100 [1] | $1000 | 1 | 250 | 3.6x |
Table 1: Measured latency, concurrency
[1] P100 and P150 are expected to have the same latency for single-chip inference, since the lightning V2 doesn't do multi-chip inference and does not use QSFP, the latency is expected to be the same as that of P150. The measured latencies are that of P150.
Why This Matters
Lightning V2 was not simply quantized and deployed.
It was co-optimized with the hardware.
The NoC reduced memory pressure.
SRAM locality reduced energy cost and redundant DRAM movement.
Native BlockFloat8 reduced compute cost.
The result was not just faster inference — it was a structural shift in inference economics.
A Concrete Comparison
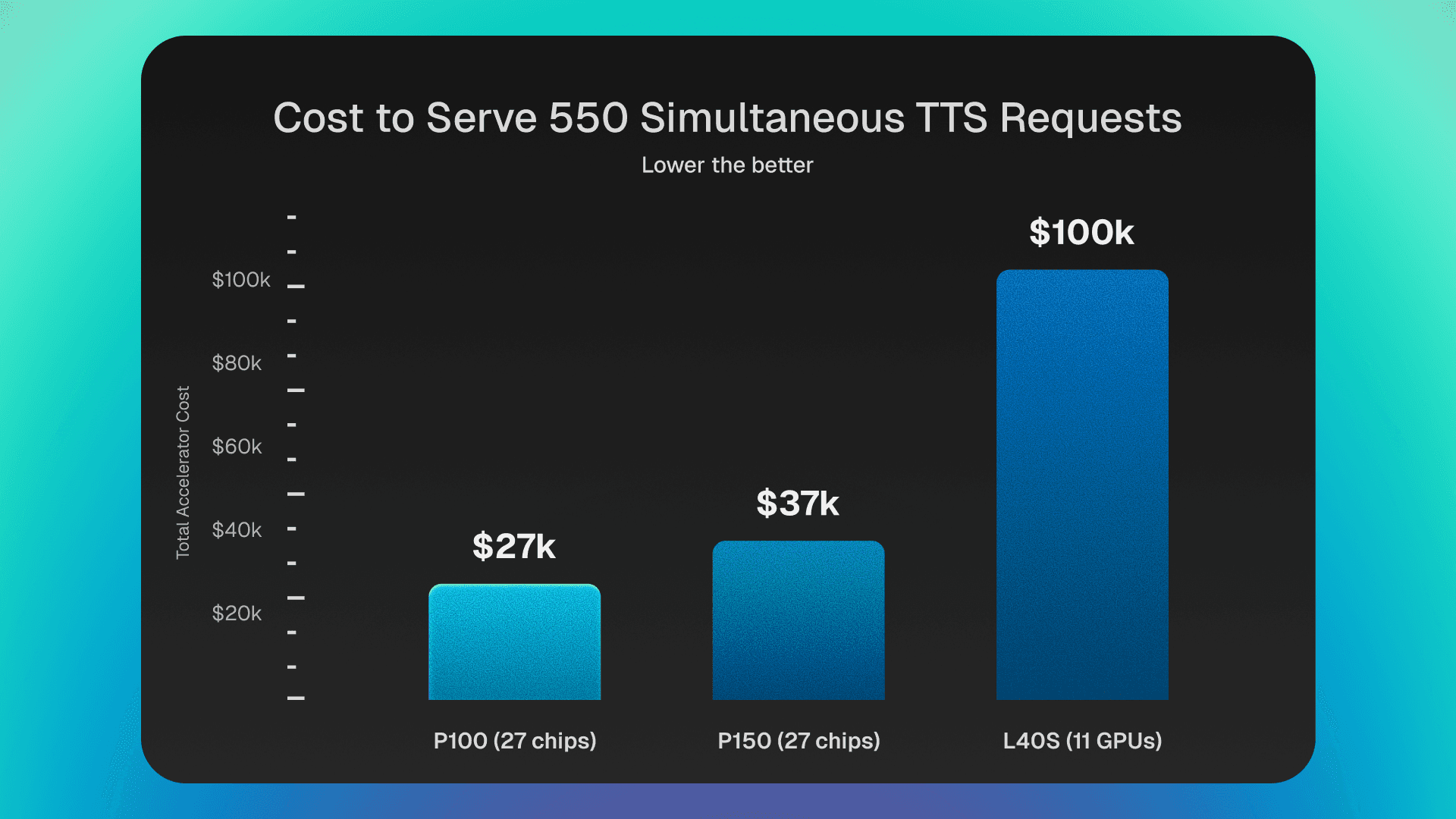
Assumption (for simplicity): Each response produces approximately 5 seconds of audio (this may vary slightly per request).
From Table 1, each L40S can produce 3.33×3×5=50 seconds of audio per second, while a P150 can produce 4×5=20 seconds of audio per second.
Consider a voice agent pipeline (AST → LLM → TTS) operating at 100% hardware utilization, where the next input to the TTS stage is always ready before the current generation completes.
To sustain a workload equivalent to generating 550×5=2750 seconds of audio within a 5-second window- corresponding to a steady stream of 550 overlapping 5-second requests at full utilization (i.e., effectively supporting 550 simultaneous calls):
Since each request generates ~5 seconds of audio, and a single NVIDIA GPU can process about 10 requests per second (based on the measured ~300 ms for 3 responses), each GPU delivers 10×5=50 audio-seconds per second. Therefore, 11 GPUs collectively provide ~550 audio-seconds per second, which is sufficient to sustain this workload.
NVIDIA would require 11× L40S GPUs, costing roughly ~$100,000 in accelerator hardware.
Similarly, Tenstorrent would require 27× P100[1] (~$27,000 total) or 27× P150 (~$37,000 total).
That is a ~3–4× reduction in upfront accelerator cost to serve the same workload.
The difference between ~$27K and ~$100K is not incremental — it is decisive. For many deployments, that delta alone determines whether on-prem inference is feasible.
Structural Impact
This shift changes the economics of TTS in three important ways:
On-prem becomes viable- without requiring six-figure GPU budgets.
Capital expenditure drops significantly, enabling smaller teams to deploy high-quality voice models.
The barrier to building voice-native applications is lowered, especially for latency-sensitive and privacy-sensitive workloads.
When inference cost drops by 4× without sacrificing audio quality, new deployment models become practical. Real-time speech systems are no longer constrained to high-end GPU infrastructure.
This is not just a performance improvement.
It is an economic unlock.
Future Work
Lightning V2 on Tenstorrent represents a major milestone. Our latest model, Lightning V3, already surpasses V2 in quality and architectural efficiency. We plan to deploy Lightning V3 on Tenstorrent with the same co-design principles, targeting similar or greater cost breakthroughs.
Kernel and Program Optimization
While the current results demonstrate strong hardware leverage, several program configurations are still sub-optimal. There remains significant headroom.
To illustrate the potential:
One heavily optimized layer (~6B MACs) currently takes:
~60 μs on NVIDIA L40S
~31 μs on Tenstorrent P100 [1] and P150
This demonstrates that when layers are fully optimized to exploit Tenstorrent’s architecture, performance improvements are not incremental — they are multiplicative (18x -> 2x better on a device that is 9x cheaper).
Extending this level of optimization across more layers is expected to unlock 8–12× gains.
The objective is clear:
Not just lower cost — but structurally redefining the efficiency frontier for real-time speech inference.
Read more on this in our paper: https://arxiv.org/pdf/2604.03279

