

Open source vs commercial speech-to-text APIs compared on WER, latency, deployment, pricing, and integration so you can pick the right STT stack for your product.
Speech-to-text infrastructure is increasingly splitting into two camps: self-hosted open-source models built for control, and managed APIs optimized for production deployment speed. This decision frames one of the most critical choices for teams building with voice: whether to own the model and its operational overhead or to integrate a managed service that abstracts the infrastructure away. Choosing between open-source and commercial speech-to-text APIs impacts everything from data privacy and infrastructure spend to the engineering resources required to maintain a production-grade system.
This decision rarely comes down to a simple evaluation of “free vs. paid.” It’s a practical mix of infrastructure spend, accuracy targets, privacy constraints, and the amount of engineering time you can afford to burn on keeping models healthy in production. Below is a direct comparison of the trade-offs, the leading options in each camp, and a recommendation you can map to your use case. If you want the wider market context first, the top speech-to-text APIs roundup is a useful baseline.
How to Evaluate Speech-to-Text APIs
Before you line up vendors, align on what “good” actually means for your product. A research group transcribing hours of audio overnight optimizes for very different things than a team shipping a real-time voice agent. The six criteria below work across open-source and commercial options, and they’re the lens used for every comparison that follows.
Evaluation criteria used throughout this comparison:
Word Error Rate (WER): The percentage of words transcribed incorrectly. Lower is better. Leading commercial APIs now achieve low conversational WER, though real-world results vary significantly with accent, noise, and domain vocabulary.
Latency: Time from audio input to transcript output. Critical for real-time applications like voice agents and live captioning.
Deployment model: Managed cloud API vs. self-hosted. Affects data privacy, infrastructure cost, and operational overhead.
Language and accent coverage: Number of supported languages and robustness across regional accents.
Operational scaling model: Managed infrastructure vs. self-hosted compute.
Integration effort: SDK availability, documentation quality, and time-to-first-transcription for a new developer.
Six criteria that separate a good STT API from the right one for your specific use case.
Open Source Speech-to-Text: What You Actually Get
Open-source speech recognition isn’t a science project anymore. One of the most widely used open-source STT models is OpenAI’s Whisper: it offers multilingual language support and is commonly evaluated for multilingual transcription deployments. Vosk is another common option, especially when you care about edge and offline deployment. Coqui STT is no longer actively maintained, but it remains useful as a reference point for teams that need full control over training and deployment.
The upside is straightforward: no per-minute meter running, end-to-end control over the inference pipeline, and the ability to keep audio entirely inside your own environment. In regulated contexts where audio can’t leave a private network, self-hosting an open-source model may be required when audio cannot leave a private network.
The bill shows up in engineering hours. Running Whisper at production scale means GPU provisioning, batching strategy, model versioning, and monitoring that’s good enough to catch regressions before your users do. A 2023 benchmarking study published in Frontiers in Big Data found that paid STT services generally showed better accuracy and speed than open-source alternatives, while performance still varied significantly based on the input audio and dataset. That nuance matters: open-source doesn’t automatically lose on accuracy, but getting to parity often takes careful tuning against your specific audio profile. For a structured look at the leading options, the best open-source speech-to-text APIs breakdown covers Whisper, Vosk, and others in detail.
Where open-source STT has a genuine edge:
Data sovereignty: audio never leaves your servers, which matters for healthcare, legal, and financial applications.
No vendor per-minute billing: high-volume workloads can become cheaper once compute, storage, monitoring, and engineering costs are amortized.
Model customization: fine-tune on domain vocabulary (medical terms, product names, jargon) without vendor lock-in.
Offline capability: Vosk and similar lightweight models run on edge devices without any internet dependency.
Where open-source STT falls short:
Operational overhead: GPU management, scaling, and uptime are your responsibility.
Latency at scale: streaming real-time transcription with Whisper requires significant engineering to match commercial API response times.
No SLA: community-maintained models have no guaranteed uptime or support response time.
Speaker diarization and punctuation: features that commercial APIs include by default often require additional models and glue code in open-source setups.
Commercial Speech-to-Text APIs: Managed Infrastructure and Operational Tradeoffs
Commercial speech-to-text APIs turn transcription into a simple contract: send audio, get text back. The vendor owns the infrastructure, scaling, and day-two operations, and you pay for that through per-minute or subscription pricing. The proprietary vs. open-source STT split is convenience versus control. Still, “convenience” doesn’t capture the whole value: managed scaling, built-in speaker diarization, advanced features like low-latency streaming performance, plus enterprise SLAs when reliability is non-negotiable.
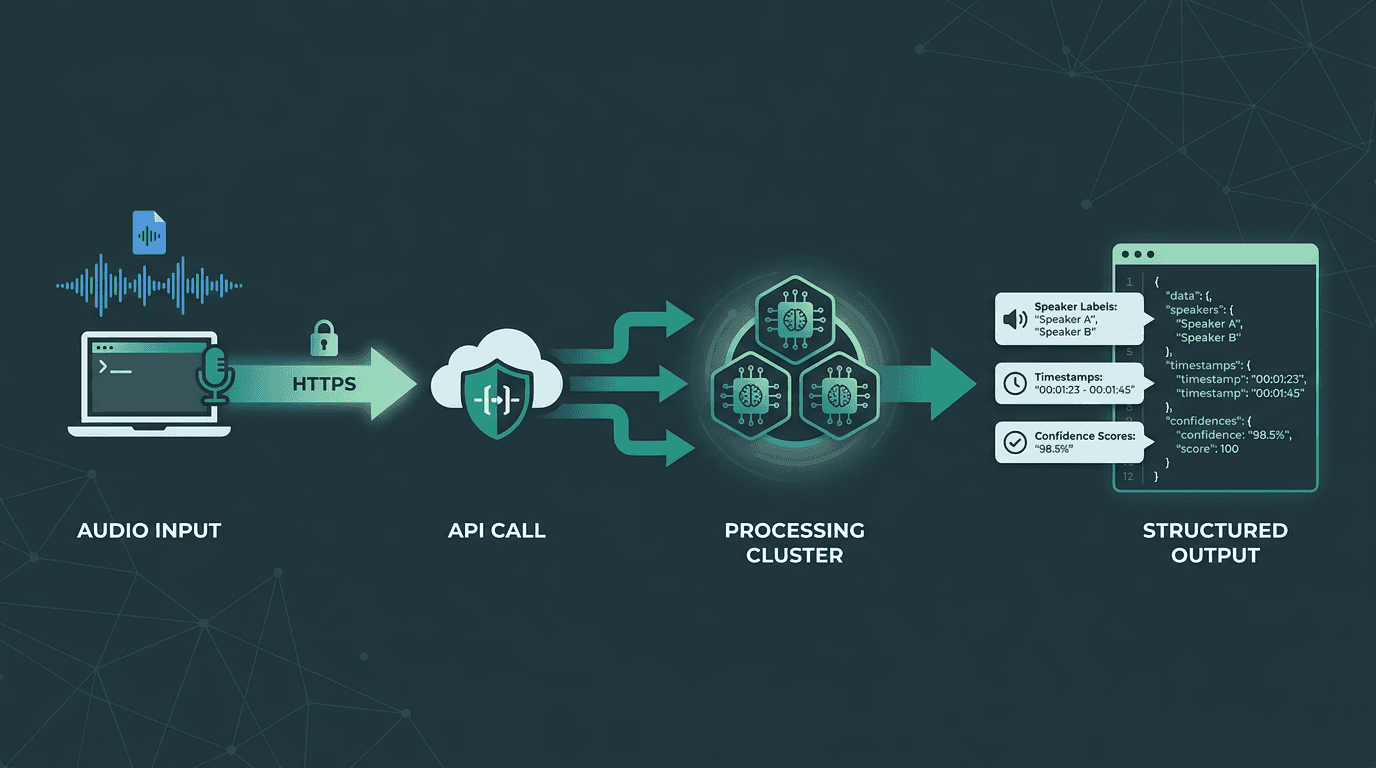
A typical commercial STT API request-response cycle, from audio input to structured transcript output.
AssemblyAI positions its platform around transcript-processing and audio-analysis workflows. It’s aimed at developers who want a combined transcription and transcript-analysis workflow. Enterprise pricing varies by workflow complexity and transcript-processing usage.
ElevenLabs came to STT from the other direction: it’s an extension of a voice platform rather than a transcription-first company. The transcription piece is positioned as part of a broader voice-generation workflow, and it is generally evaluated by teams already operating inside the ElevenLabs voice platform. Speech-to-text access is bundled within broader voice platform plans.
Deepgram positions Nova-3 around enterprise streaming transcription workflows. It offers models that support low latency for real-time use cases. Commercial usage is structured around metered enterprise transcription workloads.
Smallest.ai Pulse: Built for Real-Time Voice Applications
Smallest.ai’s Pulse is the speech-to-text product inside a larger voice AI stack that also includes Lightning (TTS), Hydra (speech-to-speech), and Atoms (voice and text agents). That framing matters, because Pulse isn’t positioned as a generic transcription endpoint. It’s built to be the listening layer in real-time conversational pipelines, where the hard constraints are latency and accuracy under live conditions.
If you’re building voice agents, the connection between Pulse and the rest of the Smallest.ai stack reduces the glue code that usually sits between separate STT, LLM, and TTS vendors. The speech-to-text for voice agents guide explains why that kind of integration changes the latency math in real-time systems. Book a demo to benchmark Pulse on your own audio profile.
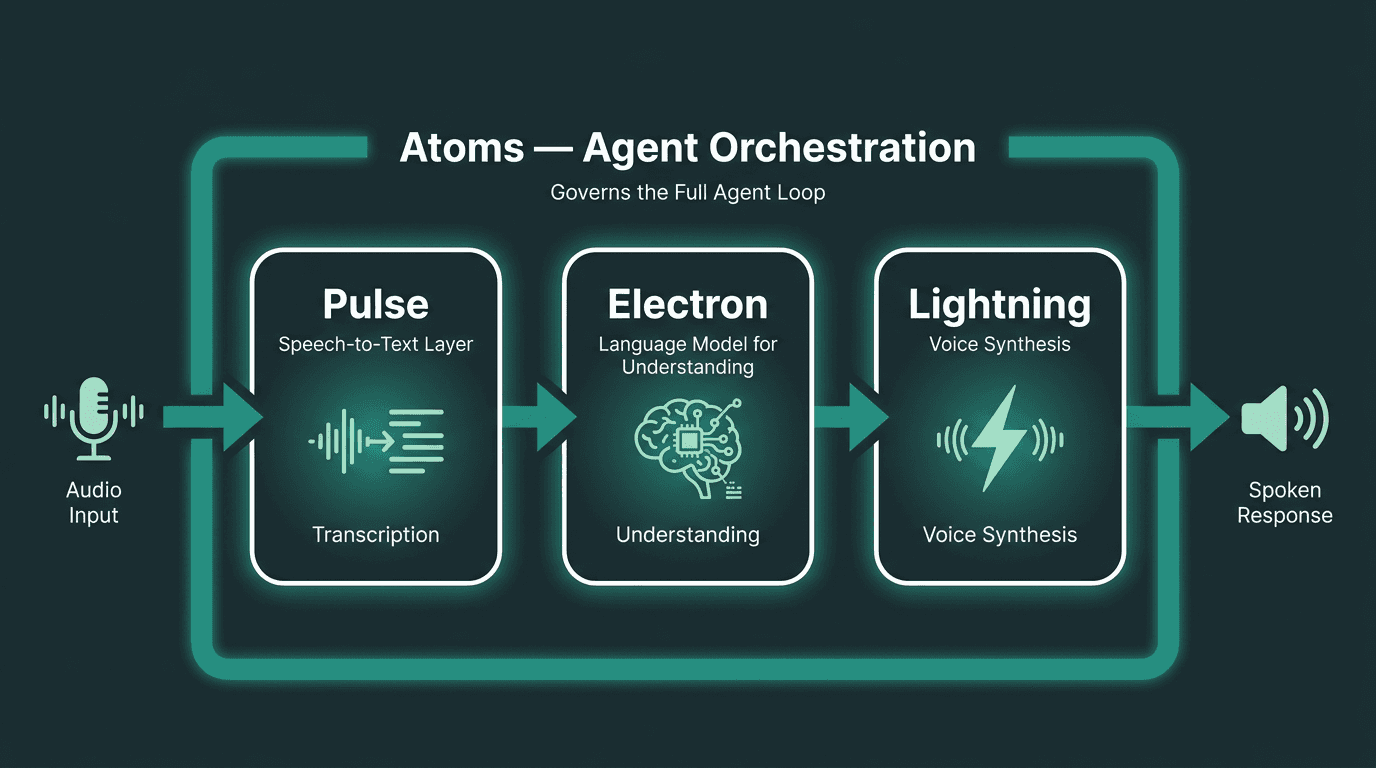
Pulse operates as the STT layer within Smallest.ai's integrated voice AI stack, reducing inter-service latency in real-time agent deployments.
Head-to-Head Comparison Table
Option | WER (English) | Real-Time Latency | Deployment | Language Support | Typical Deployment Pattern |
|---|---|---|---|---|---|
Smallest.ai Pulse | Low conversational WER | Ultra-low (optimized for agents) | Cloud API | Multilingual | Integrated conversational AI pipelines |
AssemblyAI | Competitive conversational accuracy | Moderate (streaming available) | Cloud API | English-primary, expanding | Transcript-analysis workflows |
ElevenLabs STT | Competitive | Moderate | Cloud API | Multilingual | Voice-generation-adjacent workflows |
Deepgram Nova-3 | Low conversational WER | Low (real-time focus) | Cloud API | Multilingual language support | Streaming transcription deployments |
OpenAI Whisper (OSS) | Low WER on clean audio | High (batch-optimized) | Self-hosted | Multilingual language support | Self-hosted multilingual transcription |
Vosk | Higher WER than cloud enterprise APIs | Very low (edge-optimized) | Self-hosted / Edge | Multilingual language support | Edge devices, offline, resource-constrained |
Operational Tradeoffs Between Open-Source and Commercial STT
Open-source and commercial STT systems optimize for different operational constraints. Open-source deployments prioritize infrastructure control, offline capability, and deployment flexibility, while commercial APIs prioritize operational simplicity, streaming performance, and managed scaling. For real-time conversational systems, infrastructure cohesion between transcription, language understanding, and synthesis layers often matters more than marginal benchmark differences between standalone models.
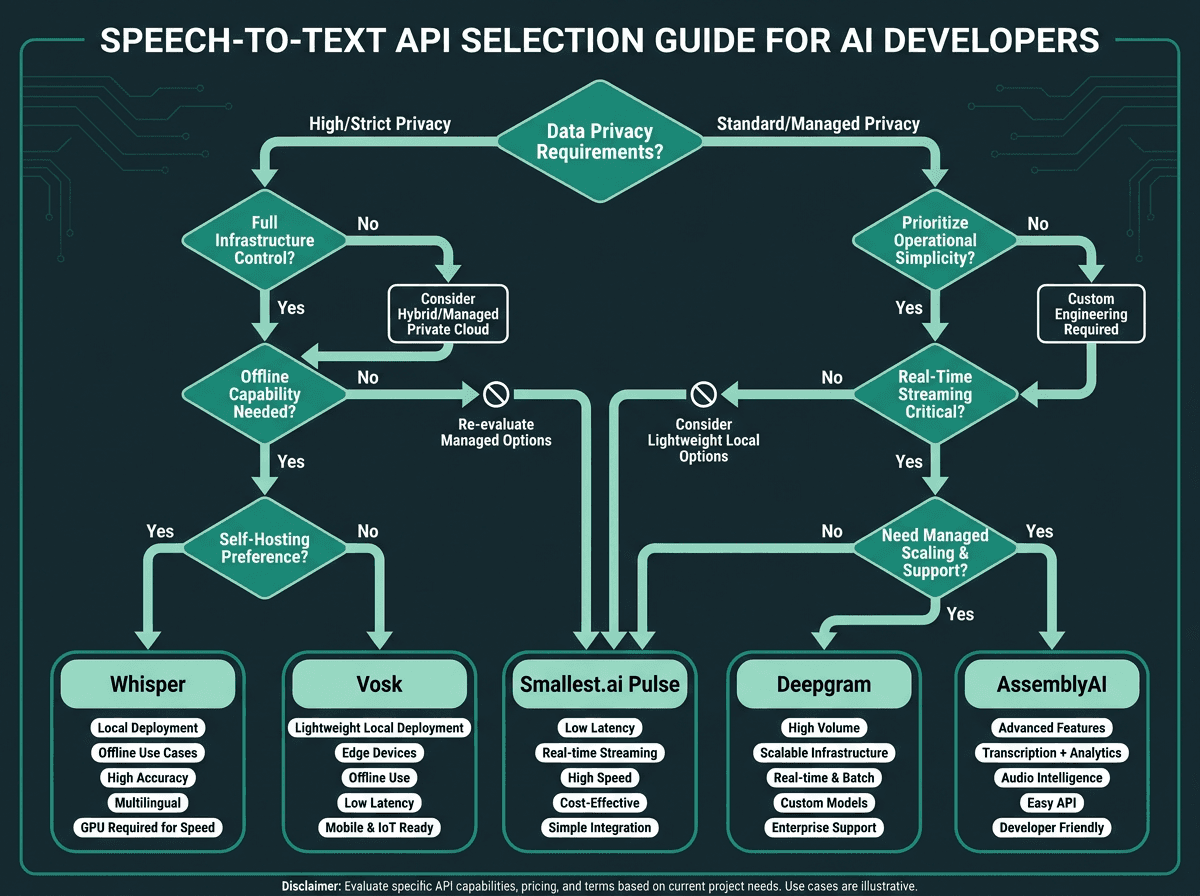
Use this decision path to match your constraints to the right STT category before evaluating specific vendors.
The Problem This Decision Actually Solves
This comparison isn’t really about chasing the lowest WER number on a chart. The real question is how to ship a reliable, low-latency voice product without spending half a year building infrastructure you don’t plan to differentiate on. Open-source models address cost and control, then hand you an infrastructure and operations workload. Piecemeal commercial APIs solve individual components, but the integration burden (and the latency you accumulate as you chain STT, LLM, and TTS across vendors) adds up quickly.
Smallest.ai’s stack - Pulse for transcription, Electron for language understanding, and Lightning for synthesis - is designed to turn that multi-vendor chain into a single pipeline. For teams building voice agents or conversational products, that architectural coherence often matters more than a marginal WER delta between otherwise strong models. If you’re actively evaluating paths, Book a demo and run Pulse on your real audio to see how it maps to your latency and accuracy requirements.
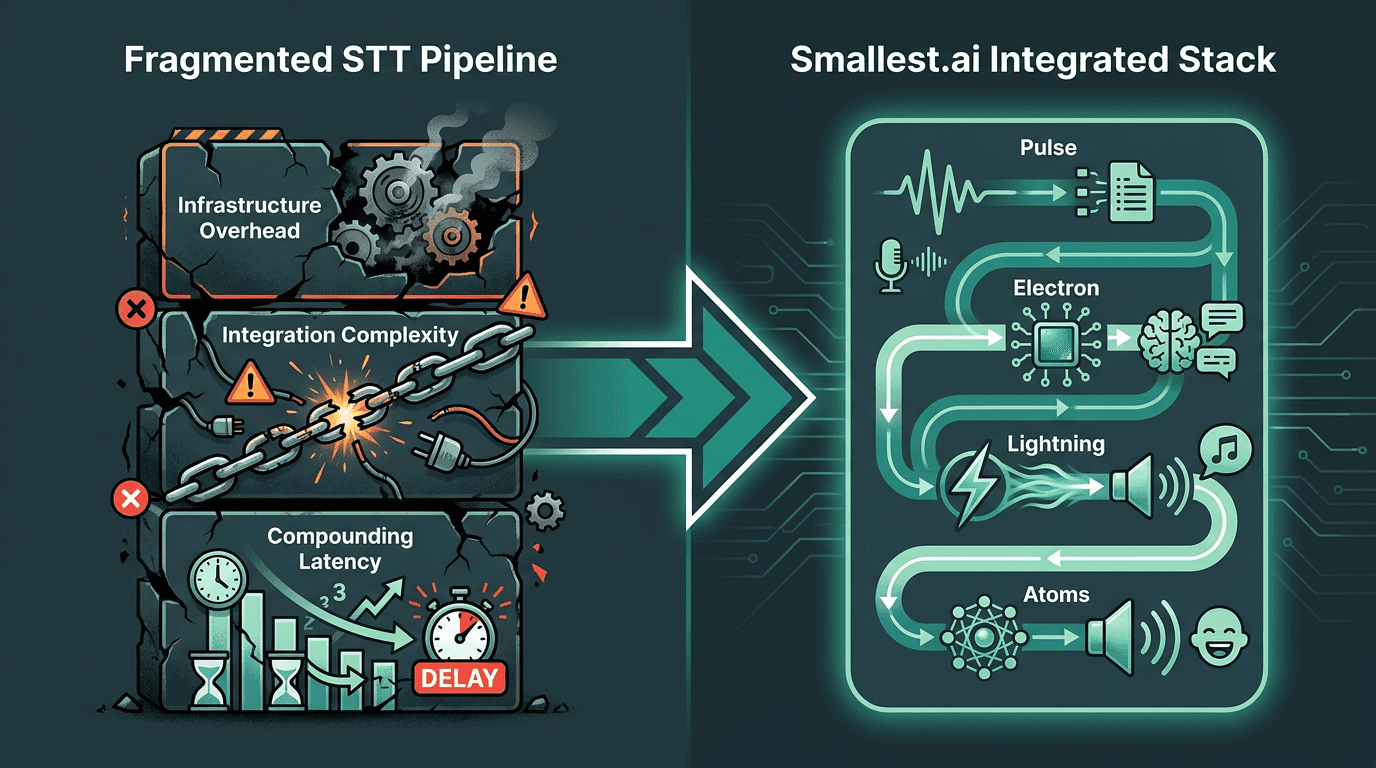
Fragmented STT pipelines create compounding latency. An integrated stack removes the seams.
What separates open-source from commercial speech-to-text APIs?
Is open-source STT accurate enough for production?
Which speech-to-text API is best for voice agents?
How should teams choose among commercial speech-to-text providers?
Can an open-source STT model be paired with a commercial TTS?

